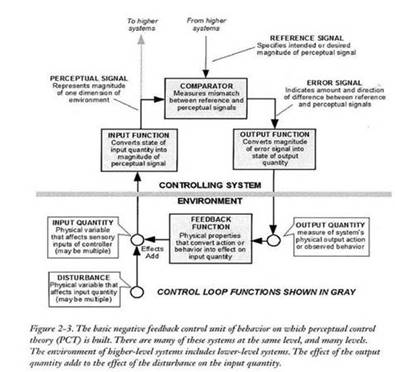
···
On 2019/05/6 5:36 AM, Bill Leach
( via csgnet Mailing List) wrote:
Bill, we obviously have some very different visions of some
things, while apparently agreeing about others. How to disentangle
the strands of thought and their foundations so that we can figure
out what each other tries to say seems to be rather difficult. But
it’s worth trying. In this message, for example, it’s clear that I
said some things that I thought were clear but obviously were not,
with the result that you criticized ideas that I did not intend
you to think I held. So let’s see whether my comments below will
bring us closer to convergence.
wrleach@cableone.net
Martin,
How so? Rick says that only one of the
wife/mother perceptions of the ambiguous figure can be correct,
and there has to be some way to know which, if the concept of the
RREV is to be useful. You, on the other hand, quite correctly say
that if two perceptions of something in the real world are
sufficiently incompatible, at least one of them has to be false.
This is not the same claim.
Now if what you are saying is that in the real world there is a
real wife or a real mother-in-law but not both, I would say this
this is rather improbable. For one thing, when w encounter a
woman, she moves, she has varicoloured skin and clothing. I
suggest that it’s more probable that in the real world there is a
configuration of dark and light patches on a nearly plane surface,
and that configuration is somewhat similar to a configuration of
two different possibilities for what it might be intended to
represent.
The claim that "that Rick has some secret means of knowing "
should not be inferred. I think the whole point of Rick’s (and
for that matter my own) position is that we can not know the
accuracy of any perception to the point of certainty.
Well, that certainly concords with my view,
but it is not what I understood from reading what Rick wrote. If
it is what he meant, I apologise for misunderstanding, It does
not, however, correspond with the implication that follows – that
one must know the level of accuracy of any perception.
What puzzles me is why this must be so. According to PCT, the lack
of need-to-know what is in the Real World is one of the key points
that distinguish perceptual control from other approaches to
control, which DO require knowledge of what is out there in order
to compute what to do about a mismatch between perception and
reference. What is really out-there (the RREV) matters, but all
you have access to is the CEV, which is, as Rick says, the
perception.
The above paragraph is a correct
interpretation of PCT as far as I know, I’m just not sure why
you mention it here and now.
To distinguish between the complex vector of
conscious perception and the scalar variable of the perception in
every control loop in the hierarchy described by Powers.
Conscious perception is of a mesh of interacting “things”
(discussion of that word later). Any perception controlled in the
hierarchy is the value of a single variable, with no concern about
its influence on other variables, either in the form of
side-effects of control actions or in the form of how context
might affect the perceptual variable being controlled. Context is
something one can consciously perceive, and its effect on
controlled variable can be illustrated in many different
situations at many different perceptual levels. It appears in the
hierarchy only in what sensed variables contribute to the inputs
of a perceptual function. But what is controlled in the hierarchy
is the value of a variable, such as lightness, freedom, distance,
loudness, morality, or any other that has been reorganized so that
it can be non-consciously controlled.
I think we are on a slippery slope of
just what do words actually mean to each of us here. Usually,
‘things’ refer to what we call physical objects. If that is
the meaning of the first sentence then I disagree. If OTOH
you are basically calling anything that is a perception a
‘thing’ then there is nothing to discuss.
Neither. The problem here is the distinction
between conscious perception on the one hand, and both control in
the hierarchy and the “knowable” aspect of Real Reality on the
other two hands. It’s also a difference in common-language usages.
I consider a “thing” to refer, for example, to the experience one
might have on viewing a total solar eclipse. You would not.
Considering the implications of either meaning, both come down to
the set of effects or influences that happen within the “thing”
and between the “thing” and everything else that is not the
“thing”.
There is an old philosophical conundrum, as to whether I am the
same identifiable person as I was years ago as I am now, given
that probably nearly every atom that was in my body then is no
longer in my body, though lots of atoms that were somewhere else
are now part of me. If you think only of the pattern of influences
among my parts, they don’t care which molybdenum atom is now in my
body or where it was three years ago. They don’t change with the
identity of the atom. But if it exchanged for an atom that was not
molybdenum, the pattern of influences would change (and I might
get sick). The same applies to any “thing” that has parts. If you
break one part and replace it with another, the “thing” is usually
considered to be the same “thing” (unless it was an antique whose
value is to be assessed).
I know that whenever I personally have
performed the tracking task, I was not conscious during the
task of other relationships unless I decided to be curious
about another relationship (which probably impacted my ability
to perform the tracking task adversely). That during control
many potential perceptions are not detected by the subject is
a given in PCT. It is also recognized that some such
perceptions might be detected and result in a change in
behavior on the part of the subject.
Are you actually saying that you don't see the
cursor and you don’t see the target, but you do see the distance
between them in one specific direction?
In the rest of this paragraph you are
using a physics approach to describe what is actually
happening rather than the common language. It isn’t wrong but
it is clumsy and would make a discussion of specific cases of
tracking far more difficult to discuss unless such detail
assisted in understand why some result failed to match
expectations.
Yes here is a solid case of misunderstanding.
I was simply trying to say that there’s a difference between
moving an object as a coherent unit and moving its parts
separately so than their interrelations never change. Another
example: if you have twenty checkers pieces on a board in the form
of a cross, and you want to move the cross to another place while
keeping it all together as a cross while you move it, you will
need twenty hands (unless you are very dextrous). If you have a
wooden cross lying on the board and want to move it to a different
place, you pick it up at one place and put it where you want it,
all the while keeping its cross shape. The point is made even more
strongly with a real-life example of trying to raise a wooden
ancient ship from where it sank centuries ago. The problem is to
prevent it falling apart while it is being lifted.
I used the computer example because I wanted to use the internals
of the computer as a metaphor for the unknowable Real Reality
later in the message. The computer can manipulate all the parts of
the cursor and target well enough to make whole objects seem to
move together, but throughout the exercise, the relationships
among the parts, however they are represented in the computer are
influenced by the computer to stay unchanged, even if they are
distributed throughout the machine at some pints in the process
(our brains do the same, with the myriads of nerves and synapses
that are represented by one “bundle” that carries a “neural
current”.
This paragraph had the programmer in me
laughing heartily! Of course you are right in that a cursor,
as a physical object, does not exist in a computer. Neither
does a pointer. Of course a ‘stack’ is a little harder to
claim as being non-existent.
However, I still don't see where the fact
that a cursor does not actually exist matters. In the
tracking task we define the cursor to exist—so where is the
problem?
We perceive the cursor as an object, a
configuration of spatial relationships, that exists. We define it
to be a cursor when we label it. The “problem” is that we act on
one single-valued property of the object, its location in one
dimension. The parts of the object may be (we don’t know in the
metaphor) distributed, but the configuration is not lost. It is
translated and can be further (or re-) translated into the
language of pixels on a screen. At another level, the problem is
that there seems to be some notion that in Real Reality the
objects we perceive must have the same form as they do in our
conscious perception. There’s no reason even to suspect that might
be true, because, as the computer metaphor was intended to show
what matters is that the entropy of the structure in not
increased, The configuration you perceive yourself to be moving is
the same before the move as it is after the move.
Your RREV in this case is already flawed.
I’d be happy to point out that there are millions of computers
that have less than a dozen chips total! Even I admit that my
claim is irrelevant but it does point out that the idea of a
formal RREV is a lost cause.
Why and how? I see no connection at all with
the foregoing.
There is one tracking task that I
remember that reversed the sign of the mouse signal (it is
actually far more complicated that a simple reversal, but that
is the effect). The point demonstrated by the task was that
the first time a reversal happened quite a bit of time
(relatively) was needed to recover tracking, but as subsequent
reversals occurred the subject became much more skilled at
both detecting and correcting the disturbance.
Yep, reorganization works! And it doesn't
always have to be slow.
I'm thinking that there was another
tracking task that just changed the ‘mouse gain’ so that the
amount of cursor movement for any given mouse movement was
altered. And as I recall this task demonstrated that such an
additional disturbance had very little effect on ability to
control.
Yes indeed. I've done such tracking studies
myself. But what does it have to do with anything in this thread?
If you say so but, I still do not see where
that is relevant to PCT.
Aayeah, that is our mutual problem, isn't it?
I don’t see how most of your critiques relate to the point I try
to make, and you don’t see why the point you think I am trying to
make relates to PCT. I’m trying to make an argument that even
though everything we perceive is derived from Real Reality about
which we can know nothing except that when we perceive some
pattern of functions of sensory inputs and execute some pattern of
actions Real reality serves up some changed pattern of sensory
inputs, in a loop, nevertheless, what we actually perceive
produces very much the same pattern of influences from output to
input as does Real Reality. If this were not so, we could not
control.
It's an argument made by Norbert Wiener half a century ago about
figuring out what a black box does when you can’t look inside it
at all, but have access to a bunch of input terminals and a bunch
of output terminals. Wiener said that it’s a lost cause trying to
figure out what is inside the black box. The best you can do is
try to make a white box that has the same bunches of terminals and
produces the same outputs as the black box when confronted with
the same inputs.
Wiener's solution was to construct a library of trivially simple
white boxes. An electrical engineer might have some resistors,
diodes, amplifiers, capacitors inductors, adders, multipliers and
such like as the basic white boxes, but it really doesn’t matter
what they are, so long as the constructor understands them and
they do enough different things. Put them together in different
configurations and the structure does new things that the elements
don’t do individually. If we think of the basic white boxes as
atoms, the collection that is linked together is a molecule.
Having got a basic library of atomic white boxes, Wiener creates
molecular white boxes and polymer while boxes and so on, always
reorganizing to improve the fit between what the black box does
and what the big white-box envelope does.
I imagine the perceptual functions as producing perceptions/CEVs
that interact together in the manner of Wiener’s white boxes,
reference input functions as creating unitary actions for which we
have no name, but are more of the white boxes, and the whole
structure of white boxes passing mutual influences being the
perceived environmental feedback path that completes control loops
that reorganization/evolution keeps changing, on average to a
better and better match to what Real Reality does.
But as Wiener pointed out, there's no way of knowing how the black
box does it. All we can know is that our structure of control
loops that control our perceptions allows us to control
effectively as though those loops were the ones that actually pass
through Real Reality and determine how our actions affect our
perceptions. However Real Reality operates, whether by my Gnomic
bureaucracy, by some distributed system, or by something more like
what we perceive, to every CEV there is an RREV that has the same
pattern of influences with other RREVs as does the CEV with other
CEVs that we perceive to exist in the outer environment. But the
fit is never exact, so the pattern of influences among CEVs is
always being reorganized to make the fit better.
The first time I ever saw one of these
images I was initially unaware that there were actually two
images however, before anyone said anything and even before I
said anything to the person that showed the image to my, I
‘saw’ the second image. I was NOT expecting that there was
one. Why that happened and why I saw one before the other is
something I never thought about until reading the above.
I also am missing why this would be
outside the existing hierarchy.
Because flip-flops require lateral
interconnections that form a nonlinear positive feedback loop that
can stabilize at a limit where only one at a time is “on”, and
that one stays on even if the evidence begins to favour the other.
Flip-flops exhibit hysteresis. The basic hierarchy does not admit
them because of the within-level cross-links.
Other research is very suggestive that
the human brain is very pattern sensitive and ‘looks’ for
patterns in most data. Research also suggests that the brain
is continually trying to fit existing patterns into larger
patterns.
Exactly. That's the point of Wiener's
black-box-white-box approach that I suggest is what evolution and
reorganization do.
I'm ok until the last 2 sentences. The
tracking tasks are NOT modeling humans.
I didn't say they were. I said that the
tracking models were modelling humans. That, at least, is the
claim always made (unless the control system being modelled is a
non-human organism).
They are providing the target, the disturbance,
and recording the human behavior. Some of the more complex
programs incorporated into some of the tracking task programs
are able to simulate human behavior and thus predict how a
particular human (for which the computer has collected data)
will perform on a somewhat different task. Note however, that
is not a tracking task but is indeed a simulation (something
that is not needed for a tracking task).
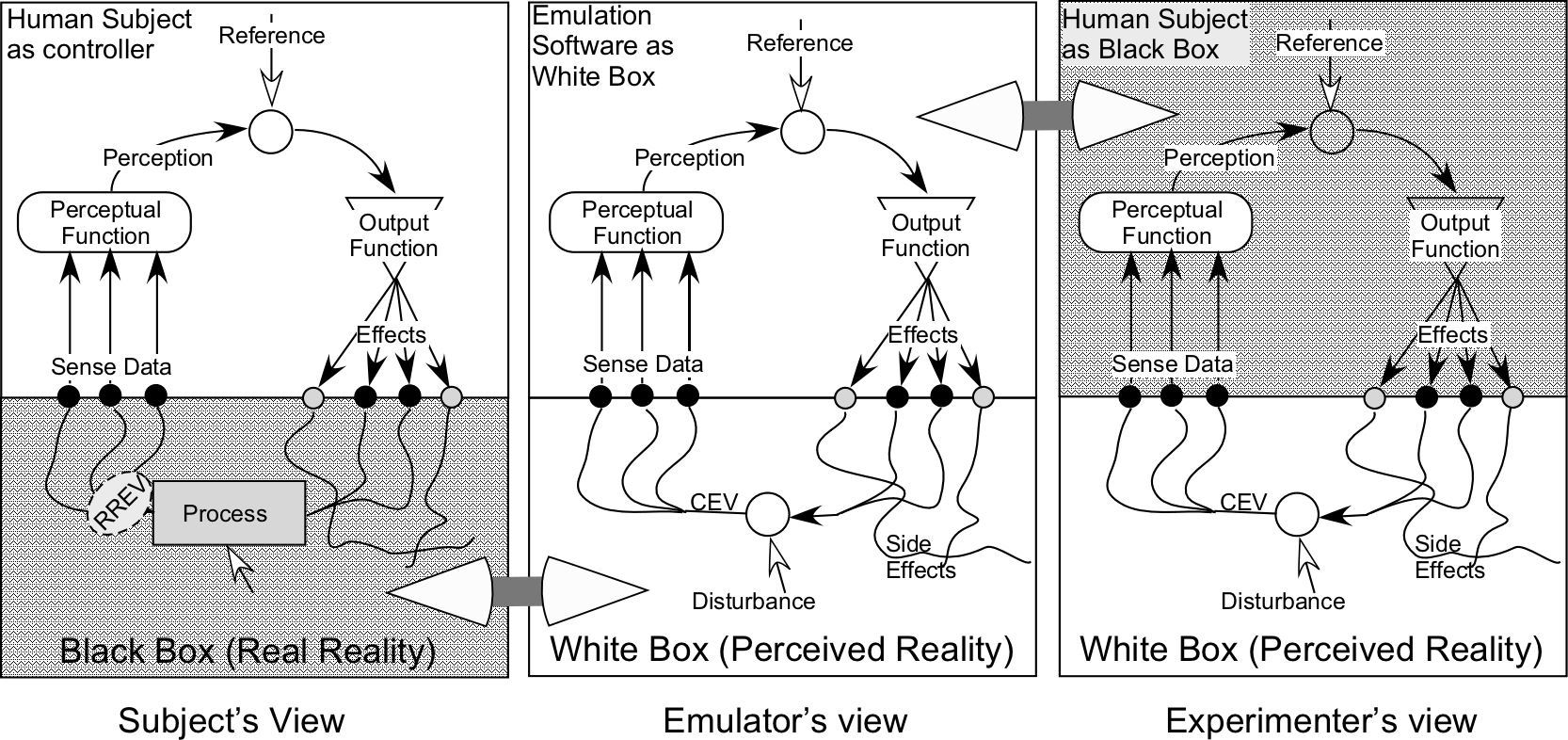
That is the point. An now you have come to the
double-black-box problem that confronts the theorist and the
subject in a grand feedback loop. Here’s a sketch of the problem
showing just one control loop, but it could be any complex of
control loops. The human controller controls a perception, working
with environmental feedback paths through RR. The emulator assumes
a set of environmental variables that are to be controlled using
control loops with various parameters and interconnections,
knowing neither the “black box” of what goes on inside the human
skin nor the black box of Real Reality, while the experimenter who
works with the human subject tries to figure out what goes in
inside the subject under the assumption that the “white box” of
the experimenter’s perceptual world matches the black box of the
world perceived by the subject. The emulator is trying to solve
Wiener’s black box problem in both places, inside the subject and
inside RR.
I suppose the point is that for each of us, everyone else is
inside the black box of Real Reality, and only if we can produce
white boxes for each other that mimic what the other does when we
act to influence their presumed perceptions will we be able to
have effective social communications. Using this new language of
black and white boxes, what I said at the start of this message
was that my white box model of you and of your white box model of
me result in ineffective control of my perceptions, problem I can
address in two ways: 1. modify my white box model of you, and 2.
try to act so that I can perceive your white box model of me as
matching my perceived me.
When I thought I was starting to
understand the RREV concept and how it might be useful (not to
PCT but to behavioral sciences such as sociology) the more I
thought about it the less enamored I became.
I find that tendency of thought very strange.
Mine has gone the entirely opposite direction.
I am sitting on a chair as I write this.
I realize that there is some finite possibility this chair
does not actually exist.
What does that mean? The chair is a perception
of a bunch of influences that allow you to perceive yourself
sitting on it. How can it not actually exist? You know that Real
Reality is what allows you to sit on what you perceive as a chair.
In what other sense might it not exist?
However, you're going to have one heck of
a time convincing my that it does not. Why call this chair an
RREV?
I don't. And couldn't, since it is a
perception you say you have.
Since it is pretty well defined, why not
just call it a chair? Do we know anything more about the
chair once we decide that it is an RREV?
Since we never could decide that the chair is
an RREV, the only reason not to call it a chair is that you might
be communicating with someone who doesn’t speak English. “Chair”
is just a label for a perception, isn’t it?
Absolutely LOVE the quote Martin!
On 5/5/19 9:54 AM, Martin Taylor (
via csgnet Mailing List) wrote:
mmt-csg@mmtaylor.net
[Martin Taylor 2019.05.05.09.10]
[Eetu
Pikkarainen 2019-05-02_09:13:00 UTC]
[Rick Marken 2019-04-24_16:12:10]
This seems to me to be a very
weird discussion of something that seems so clear to me, but
if either Rick or Eetu have a clear idea of what they mean by
Real Reality, RREV, perception, perceptual function, the
perceived environment, and similar labels, those ideas are not
clear to me. For example, Rick’s comment: * But one thing I’m pretty sure is true of the
RREV is that one’s perception of it can be correct or
incorrect. It seems to me that if the RREV is to be a
useful concept, those who invented it should be able to
tell me which of my perceptions in the wife/mother law
illusion correctly corresponds to the RREV? And I’d like
to know how one knows when one is perceiving an RREV
correctly or incorrectly. To answer this one would have to
know what the RREV is that is out there; is it the wife,
the mother in law, both or neither? Inquiring minds want
to know.
* This question seems to me to
be exactly parallel * to “Does
Vulcan pay his Smiths overtime when Etna is in eruption?
Enquiring minds want to know.”* When Rick says “* one
thing I’m pretty sure is true of the RREV is that one’s
perception of it can be correct or incorrect”* I would very much like to know why is so very
sure that a perception of what is knowable only through the
relationships between one’s actions and one’s sensors can be
found to be correct or incorrect. That assurance seems to
say that Rick has some secret means of knowing the colour of
the beards worn by the majority of Vulcan’s hired
lava-smiths – or that there are no such hired hands
producing Etna’s eruption products. Most of us have no such
privileged access to real reality.
Just the fact that we know that people have
perceptions of something in the real world that are sufficiently
incompatible that at least one of them has to be false, is
plenty of support for Rick’s comment.
What we do have is access to our perceptions, including our
perceptions of such inside-the-skin things as muscle
tensions. According to PCT, most such perceptions are
non-conscious at any moment, but some are conscious. We
never have a conscious perception of a scalar property all
on its lonesome, but nevertheless, according to PCT, we can
and do control some of them. Almost all simulations using
human subjects simulate control of isolated scalar
properties of something we perceive consciously. We don’t
control “things”. We control perceived properties of
consciously perceived things.
Conscious perceptions are of things. We don't control even
those things. What we perceive and control are some
properties of the things, and other properties go along. If
we consciously move the arrow-tip of an on-screen cursor
leftwards, the shaft of the cursor arrow moves, the distance
of the tip from the left side of the screen changes, the
distance of the tip from the right side changes, the
position of the mouse (or joystick) changes (though that may
not be in conscious perception). Most particularly, on the
screen we consciously perceive a consistent shape all moving
as a unit, even though all that “really” changes on the
physical screen is the light level emitted from a lot of
different spots on the screen. As Rick would quite correctly
say, I assume, we have not moved a cursor in a tracking task
so that it follows the target, we have only changed the
light levels emitted by a few hundred points on the screen.
But there's a problem with this view, that there is no
cursor object in real reality. The problem is that we have
no way, using the mouse or joystick, of determining how much
light is to be emitted at any moment by each of these pixels
individually. We can only move what we consciously perceive
to be a property of a moving entity – a pattern of dots,
not a whole lot of dots that we act on so as to make them
look like a moving pattern. To change the luminosities of
those dots with the correct timing is the job of the
(presumably unknown to the subject) internal workings of the
computer. Is there a cursor inside the computer? No, because
we actually do know something of the working of the
computer, we know that there is not. What there is, is a
continually shifting flow of electrons in places distributed
all over the place in the wiring inside the box, that
results in what we see as a single thing, a cursor.
What do we control, then, in such an on-screen tracking
task? We control something generated by some perceptual
function(s) in our brain that is ultimately fed by visual
sensors, the millions of rods and cones of the retina in our
ever-moving eyeball. That something is the relative
locations of a cursor and a target, neither of which exist
inside the computer.
What does exist inside the computer that keeps the
relationships among the lit and unlit parts of the screen so
stable that we see a stably shaped cursor and target moving
in ways that we can control one property of their
relationship in some consistent way? No matter how the
effects of moving the mouse my be distributed among the
millions of transistors and hundreds of chips inside the
computer, the pattern and location property of the cursor
and of the target are never lost. They (the patterns of
relationships among the properties of the cursor or the
target entity) constitute the RREV that produces the
influences on our myriads of sensors that eventually produce
a consciously perceived cursor and target in the context of
a computer screen.
What we consciously perceive, the CEV that seems to be in an
external environment, is created by our perceptual
functions. We control the perceptual value produced by one
such perceptual function – the target-cursor relative
location in, say, the x-direction. How would it be possible
to control that perception if the CEV (cursor-target
distance) was not consistently influenced by or actions that
send signals to the computer that are reasonably faithfully
related to what our myriad rods and cones report to our
perceptual hierarchy? The action effects may be distributed
among millions of transistors, but through the many stages
of influence inside the computer, their coherence as a
pattern is never lost. It can be reconstituted by our
perceptual processes through an indefinite number of stages
to finally emerge as a coherent entity (a cursor, a target,
and a relative location property of the complex.
Who cares how the "realish-reality" of the computer's
innards maintains the coherent patterns? However they are
done, whether by analog or digital means, by electronic or
Babbage’s gear-wheels, the patterns of influence are not
dissipated in the process. Internally, something always
corresponds to an entire cursor and to the location of that
pattern on the screen. The cursor shape and location are
both RREVs inside the computer, and CEVs in a consciously
perceived external reality.
As for the question of ambiguous figures, there is ambiguity
only when there must be a choice. A better question than
which is a “correct” representation of real reality might be
why our perceiving systems usually show consciously only one
of them at a time, when the data are consistent with both.
Do the perceptual functions have flip-flop type mutually
inhibitory connections? That’s not in the Powers hierarchy.
Should it be? I think that’s a better question than whether
a particular perception “correctly” represents real reality.
Real Reality determines the success of our controlling. We
control only our perceptions. Our perceptions determine –
are – the CEVs that cohere in a reasonably stable perceived
external environment. But one must ask how controlling a
perception that according to PCT is a function of several
lower-level perceptions could possibly work if the CEVs
involved did not change in ways directly related to what
goes on between action and perception in Real Reality? The
CEV-RREV relationship matters, not because real reality
“contains” an RREV, but because any influences interacting
in Real Reality are mimicked by the influences cascading
through the perceived external reality that consists of our
perceptions, The CEV reality is as much the reality of RR as
our tracking models are actual humans. They just act the
same way, so far as we can tell, if the simulations are
good.
When I first encountered Eetu, he not very successfully
tried to get me to understand the semiotician’s view. What I
understood was that a lot of it had to do more with what
influenced what than with what WAS what. What I understand
of CEV and RREV is the same. If RR contains an RREV that
influences our sensor systems, we cannot know WHAT the RREV
might be or how it is implemented. We can know that if we
can influence it and that influence has a consistent effect
on the CEV created in the perceived external environment,
then something in RR has a structure, a pattern of mutual
influences that act together in the same way as the
structural influences that constitute the CEV – the
component lower-level perceptions and the perceptual
function that determines how those perceptions inter-relate
to create the CEV.
Sorry this is so long. As Voltaire is supposed to have said,
I don’t have time to make it shorter. I hope it makes sense,
nevertheless.