[From Rick Marken (2013.03.11.1700)]
Martin Taylor (2013.03.11.00.01)–
[From Rick Marken (2013.03.10.1540 PDT)]
MT: Your message makes me much clearer about your thinking, and we may be converging. I’d still be happier if you did the model optimizing by matching the track, but at least I now think I understand the data you presented and why you think they show what you say.
RM: Great. As I said, I am in the process of matching the model to some of your tracking data. I will report back soon (well, before the end of the week) on the results of that effort.
MT: I don’t agree, however, that it resolves the issue of what perception I was controlling.
RM: I agree, the results of testing for controlled variables, regardless of how it’s done, never finally resolves the issue of what the controlled variable really is. But it gets us closer to a correct definition of that variable.
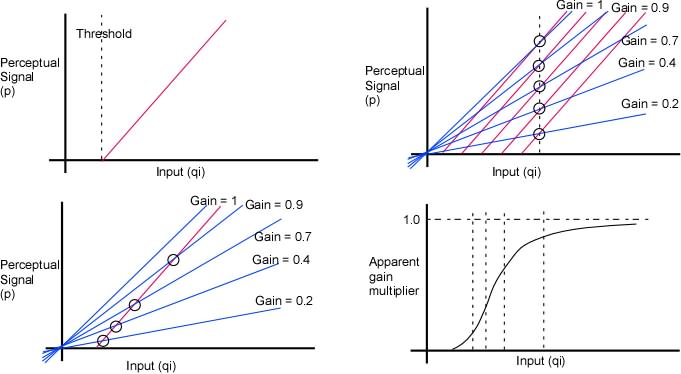
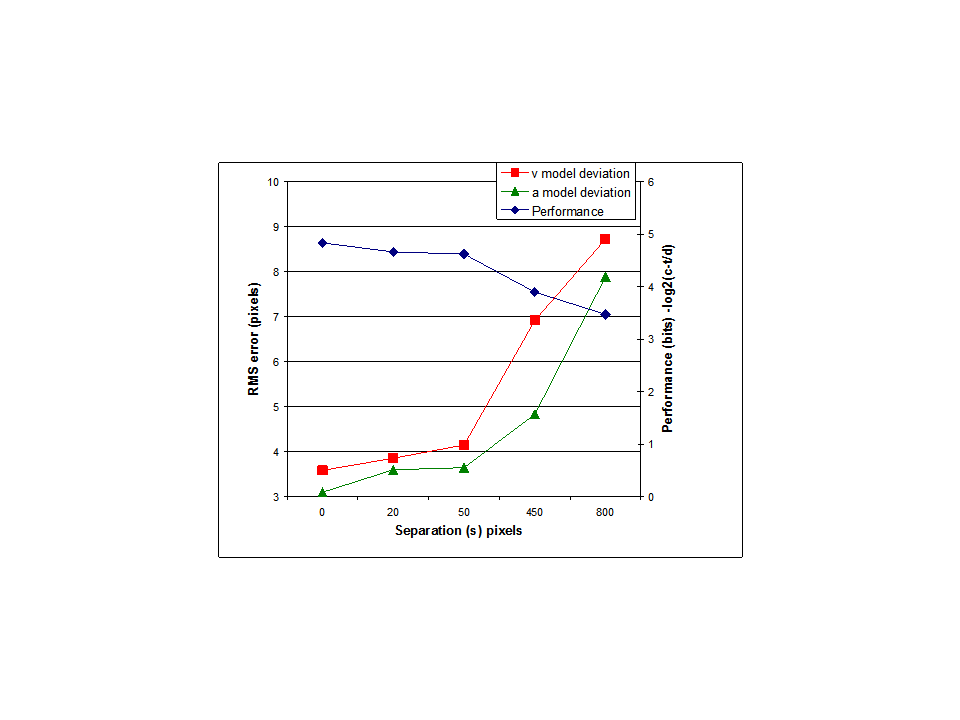
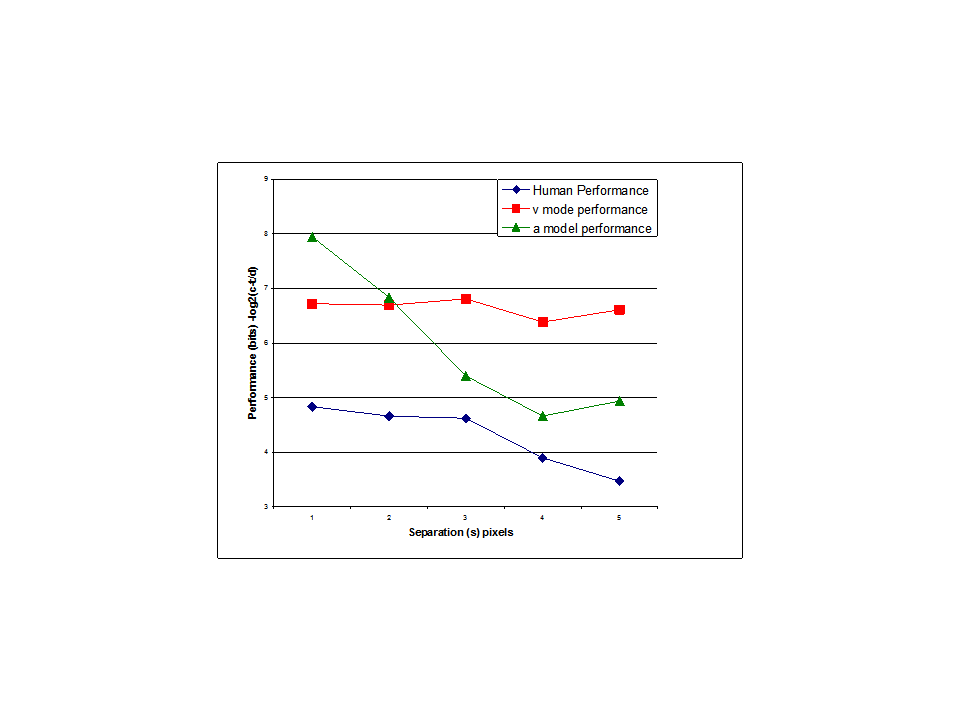
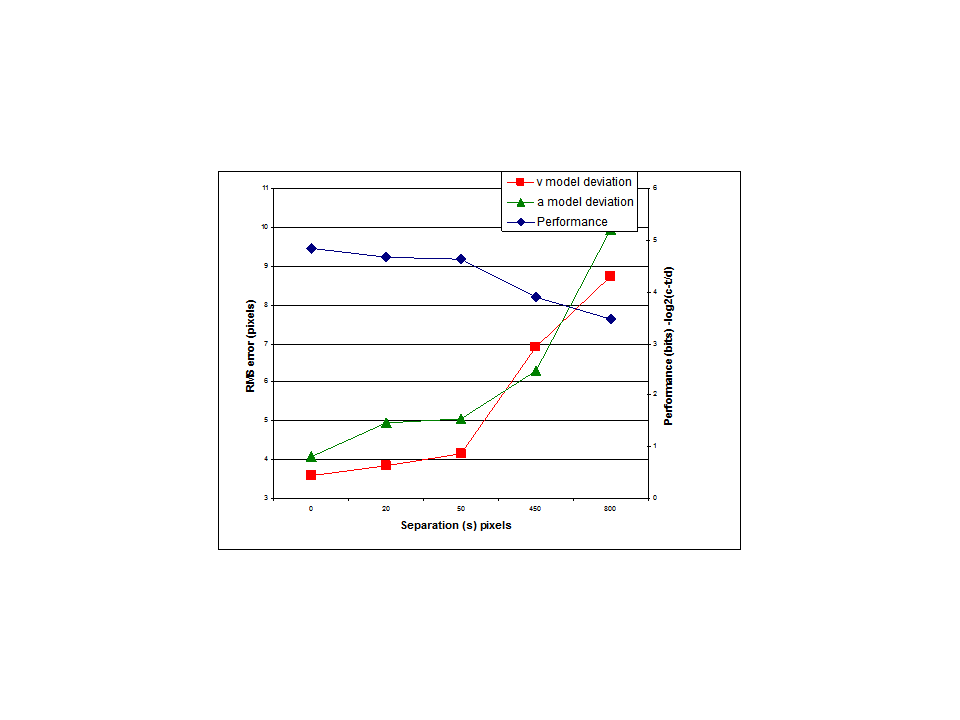
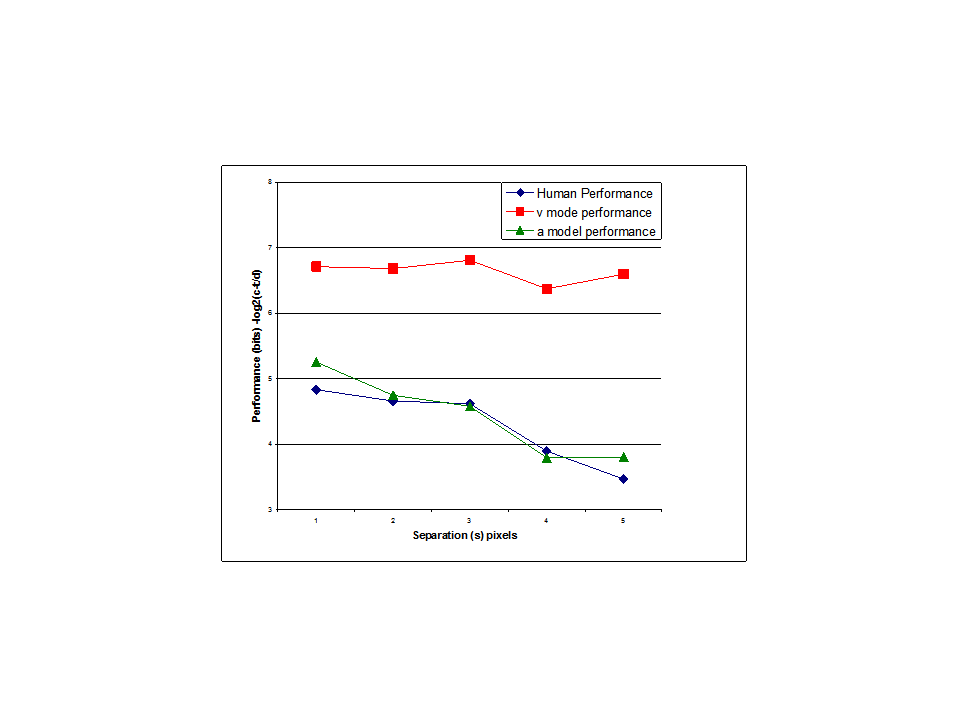
I think the results of my modeling efforts certainly suggest that the perception controlled in a tracking task is closer to arctan(v/s) than it is to v. But it can’t really be arctan(v/s) for the simple reason that this value is not defined for s=0 (when there is no separation between cursor and target) but we know that people are perfectly capable of controlling the distance between cursor and target when s=0. Maybe s is better defined as the distance between the mid points of target and cursor?
So whatever perception is controlled it is closer to arctan(v/s) than it is to v. What we need now is a clever mathematician like you to suggest function(s) other than arctan(v/s) as the perceptual function that defines the controlled variable in your task; this new function should produce the same results as arctan(v/s) when s> 0 (when the actual s in your experiment was 0 I used s=10, which was the minimal s that let the model work; so this does assume that s is the distance between midpoints, I guess).
MT: I’d like to agree, because from the start I have said that subjectively it feels as though I am controlling the angle alpha, but I can’t agree because your model doesn’t take into account the change in the ability of the subject (me) to perceive the difference in height (or in alpha) as a function of separation.
RM: So my model accounts for the behavioral data but not the subjective data? The evaluation of models based on subjective data is new to me. How is it done?
MT: That change was the reason for setting up the experiment, to test the prediction that the control ratio would get worse as the ability to discriminate decreases.
RM: I know why you set up the experiment. But I think my model shows that your correct prediction about what would happen could be accounted for without any assumptions about decreased ability to discriminate. My model accounts for the data by simply assuming that what was being controlled was arctan(v/s) rather than v. There was no need to explain the results in terms of s leading to decreased discrimination. And indeed a model that showed how control would get worse as discrimination decreases – the model you apparently advocate – was never shown.
It has simply been asserted that the ability to discriminate decreases as s increases and that this is the reason for the poorer control. What I showed is that there is no reason to assume that it is decreasing ability to discriminate that leads to decreased ability to control as s increases;my model just assumes that it is arctan(v/s) rather than v than is controlled and it turns out that the angle control model produces poorer control as s increases, just like the human subject. If you believe that decreasing ability to discriminate with increasing s is the real reason for the decrease in the ability to control then you should present your model that behaves this way and then we can test it against the data.
MT: No model that fails to take this into account can be accepted as a valid way to distinguish the two candidates.
RM: I think you are saying that a control model that accounts nearly perfectly for the decrease in ability to control with increasing s can’t possibly by right because you just know that it must be the decrease in discrimination that is responsible for this result. Is that what you mean?
RM: I’m starting to do some detailed analysis of your data now; detailed in terms of fitting the model using v or arcsin(v/s) as the controlled variable … I think the main goal here is to understand each other. Do you think you are getting a better understanding of how I have been using your experiment to test to determine what perception might be under control in this task?
MT: Yes, but as I mentioned, I don’t think you yet have succeeded in making the discrimination, much as I would like to believe you have.
RM: All I’ve done is shown that a model controlling arctan(v/s) matches the data better than one controlling v and that there is no need to assume anything about ability to discriminate differences in cursor/target location to account for the decrease in ability to control with increasing s. The next step is to do some further tests of the model to see if we can refine it a bit. If you have an alternative model, that accounts for the data based on a reduction in discrimination ability with increasing s then it would be nice to see it so we could compare it to the angle control model.
MT: For your interest, I have put in my Dropbox a snapshot of my very naively coded experiment as it was a week ago. With luck, you can download running applications with source from <https://www.dropbox.com/sh/3fvum0pajdxqga9/cdfw-dzynk/TrackerExperiment_1a>.
RM: Thanks. Very impressive. I’ll just work with the data I have from you for now but it will be nice to see how the tracking task actualy works.
Best
Rick
···
This version has interference on screen if you choose to have it. There are 5 applications, 32 and 64-bit windows, 32 and 64-bit Linux, and Mac OS X. The source code comes with each, and is also separately available in the zip file you should get from that link. I hope it works for you. I can’t really test it, because it is my own Dropbox, and maybe that allows me access where it would not allow others. But give it a shot. If it runs for you, you can at least see what I am talking about.
Supposing the link works and the application for your OS runs, here’s what you should see.
When it starts, there is a 1000x1000 pixel window with a browny-orange background. In the middle are the two ellipses, a pinkish target and a green cursor. At the top are four pull-down menus and two buttons called “Go” and “Stop”. The “Stop” button is lethal. It exits the program. The “go” button starts the experiment after you are satisfied with your menu choices. You don’t have to make any choices. If you don’t the experiment will run with default values.
The menus, from left to right are:
Speed: Controls how fast the disturbance changes. All the speeds are rather slow.
Separation: choose the lateral separation between the tips of the ellipses in pixels.
DataFolder: Choose where to store the csv file of your data at the end of the run. If you don’t choose anything or if you choose the Default, the data will be in a “data” folder in the same folder as your application (at least it is on a Mac).
Interference Level: Interference consists of N short lines at various orientations that flash different colours and move around the window. The idea was to try to interfere with the “angle alpha” perception without interfering with the height differential perception, but I don’t think it works and don’t know how to test whether it works. SO treat it as a bit of programming fun.
When you have made your selection from any of the menus you want to use to change from the defaults (which are Speed 1, Separation 180, Default data folder, zero interference), click on the “Go” button and use the mouse to move the cursor to start tracking the target. If during your tracking you are near to moving the mouse out of the window left or right, the mouse-cursor (normally hidden) will be displayed in a small white box, giving you time to bring it back toward the middle.
There is a 5 second run in period during which the background is brownish grey, followed by approximately 69 seconds (4096 frames at 60 fps) with a greyblue background during which the pursuit tracking data are being recorded, followed by 10 seconds in which compensatory tracking with a very slow disturbance (the same as Speed 0) is being recorded. At the end of that, the data are saved and the background returns to its start state, ready for you to begin a new run. If you simply click “Go” the new run will have the same settings, or you can change settings from the menus to do a different kind of run.
Data files are named SpXSepYBgZ_N, where X is the disturbance speed selection, Y is the pixel separation selection, Z is the number of interfering dazzle lines, and N is a serial number that avoids overwriting – at least until you have ten repetitions of the same conditions. The tenth version of any particular setup will be overwritten by the eleventh and subsequent ones.
You may see some debugging messages from time to time. Ignore them. Remember that although I wanted to demonstrate the effect of reduced perceptual discrimination on control performance, this whole thing was for me more of an exercise in learning to program in Processing, than an attempt at a well built experimental setup. I know of many possible improvements, and I will probably rewrite the whole thing if it ever looks as though it might be useful. You will have the source when you download the zip file, so you can write your own improvements. If you are going to do that, you will need the controlP5 library at <http://www.sojamo.de/libraries/controlP5/> (Many useful libraries are linked at <http://processing.org/reference/libraries/>.
One note: This version uses Perlin noise, which is provided with Processing. I don’t know the actual spectral parameters of the noise, so it will be hard to compare the results against other experiments with better known noise parameters.
Enjoy, but don’t complain that the programming is lousy and inefficient. I know that already.
Martin
–
Richard S. Marken PhD
rsmarken@gmail.com
www.mindreadings.com