[Martin Taylor 2010.08.29.11.13]
I begin to remember why I said "I give up". The shifting sands are
moving again.
[From Bill Powers (2010.078.28.2200 MDTE)]
Martin Taylor 2010.08.28. 23.37 --
[From Bill Powers (2010.08.14.1030 MDT)]
Martin Taylor 2010.08.24.11.04]
(re: Rick Marken (2010.08.23.1900))
MMT: Do you have an open-loop model to
serve as a check against your model? Personally, I find it
hard to think of how an open-loop model might look.
Here's one:
other inputs
>
v
Stimulus -->[some function] --> ref signal -->
Control system → response
I think this represents your diagram. "Some function" may
contain internal feedback loops but there is no feedback from
the observed response to “some function” or to the observed
“stimulus”. Overall, this is an S-R system.
I don't see much relationship between this diagram and my model.
Could you explain where in it the loop representing the dialogue
between subject and experimenter is shown?
What dialog is that?
Discussed in a long series of messages in mid-February 2009, with a
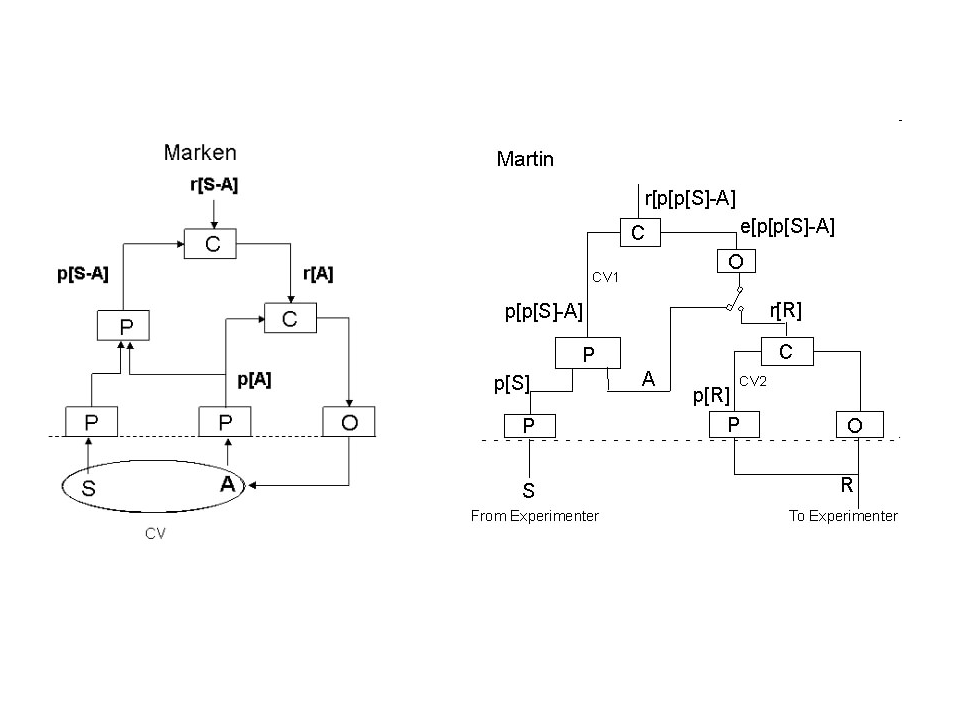
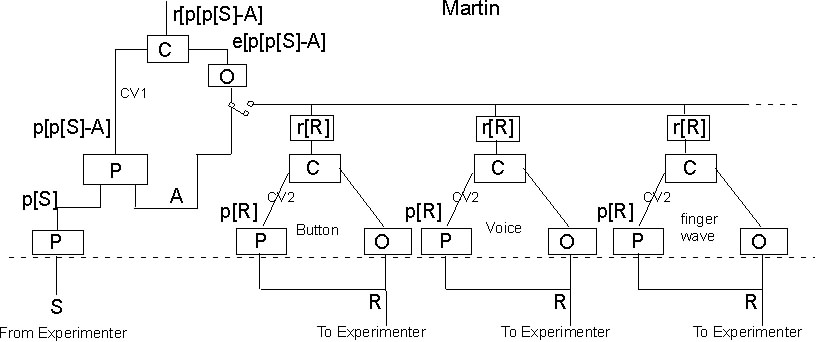
diagram in [Martin Taylor 2009.02.14.14.32] that has since been
reproduced at least once and I think more than that.
After giving the instructions, does the experimenter
tell or otherwise indicate to the subject whether each response
was correct? Does the subject have any way of knowing, during the
experiment, whether the responses fulfill the requirements of the
task? Does the experimenter do anything different that the subject
can see that depends on whether the response is right or wrong?
Discussed in a message you commended:
[Martin Taylor 2010.07.05.00.05]
The "some function" part indicates where the relationship is being
perceived and controlled in imagination, eventually leading to
setting the reference signal for the control systems that actually
produces the overt response.
Interesting that you should relegate the control loop that does the
work to the status of “some function” with “other inputs”. I wonder
why you would describe the main control system that way?
Am I right, by the way, in assuming that in your model the search
for a suitable answer occurs on every trial, meaning there is no
learning?
How could it be otherwise? The correct answer IS different on every
trial, or rather, there is nothing about an earlier trial that
correlates with what the correct answer is on this trial. So there
is no possibility for learning what the right response should be. If
you are talking about how to give the right response, meaning how to
say “three” when one wants to get across the idea of threeness, most
three-year-olds can do it, so there’s no learning possibility there,
either.
But there is learning, though not about how to give the appropriate
answer. That learning was done partly when the subject was two or
three years old and partly when the experimenter gave the
instructions. The learning that happens during the experiment is
about detecting the tone in the noise. I once did a whole summer’s
worth of detection experiments with two subjects, one of whom did
about a million and a quarter individual individual detections, and
she was still improving her performance ever more closely even at
then end of it. I think she got within about 2 db of idea-observer
performance, whereas a naive listener usually is about 6 db worse
than an ideal observer. So yes, there is learning in the experiment,
but it isn’t about being able to push button “3” or say “three” when
you want to report that the interval in question was the third. As I
said, one learns that before kindergarten, and any decent
experimenter tests that the subject knows that’s what they are
supposed to do before the experiment proper commences
[Martin Taylor 2010.07.05.00.05].
I'm on the point of giving up again. Very little of what I say seems
to have any effect on what you and Rick say about the experiment,
nor does much of what you say seem to have much relevance to
discriminating between the models of how the subject generates the
response. We agree (or at least I hope that’s still true) that
regardless of which response model is correct (if either), the
studies do correctly show the interesting property of the perceptual
input pathway, which is for me the ONLY question of interest and was
the reason I initially commented on Rick’s paper.
With that out of the way, I'm much more interested in things like
the ramifications (which I think are extensive) of the notion that a
reference value is not the output value from a higher-level control
system but is instead the output of a content-addressable memory
addressed by the output of a higher level system.
So, unless future messages build on prior agreements or give reasons
to modify them, I probably won’t respond much more in this thread.
Martin
···
On 2010/08/24 12:36 PM, Bill Powers wrote: