In Collective control as a real-world phenomenon (in Phenomena/Collective Phenomena) I posted this correction of fact:
I said I would post more detail here.
The centralization index is a measure of the relationship between two features of acoustic perception, greater intensity of acoustic energy at different frequency bands called formants. The procedure described in The Social Motivation of a Sound Change started with making acoustic spectrograms of eighty instances of diphthongs recorded from the speech of seven speakers.
A sound spectrogram is a graph with time on the x axis and rising frequency on the y axis. Sound energy falls in bands called formants. Frequency of the first formant F1 corresponds to the open-close dimension of vowel articulation (a is open, higher F1, i and u are close, lower F1). Frequency of the second formant F2 corresponds to the front-back dimension of vowel articulation (i is front, high F2, u is back, low F2). Front/back and high/low are articulatory values describing the presumed but not so often measured configuration of the tongue.
In these sound spectrograms of diphthongs, which glide from one vowel sound to another, the first formant describes a rising and falling curve, and the point of its maximum frequency was chosen to measure centralization.

This is the first vowel of the ai diphthong (as in ‘wife’), and you see F2 rising after it. If it were the same vowel but in the au diphthong F2 would not rise after it.
The relationship between peak F1 frequency and F2 frequency at that point in time, plotted on a bi-logarithmic scale, correlated with subjective (phonetically trained) impressions of vowel quality in six degrees. Two pairs were not so clearly differentiated, so this was reduced to a scale of four degrees of centralization ranging from [a] to [?].
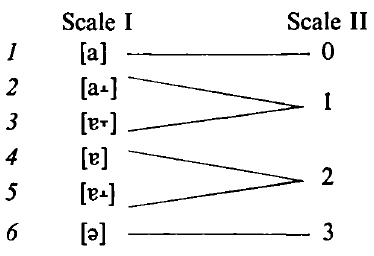
Obviously tongue position is not an imitable perceptual variable, being imperceptible inside the other speaker’s mouth. From the above, it may be seen that if the ‘centralization index’ had been a perceptual variable for the speakers in question it was not a simple perception; it is derivative of a relationship between frequencies of sound.
Experimentally, when we hear paired buzzing sounds of appropriately varying frequencies we hear speech sounds, whereas separately we hear only buzzing sounds, so clearly we have input functions that perceive vowel quality, and other functions that correlate these perceptions with the mouth-feel that produces them.
The scale above is a continuum. The differentiation into six and then four grades is a convenient artifact that Bill (Labov) could control. All that the speakers with established identity were doing was sounding “normal”, or in the case of adolescents establishing their identity, sounding “like these folks” and “not like those folks”.
In the 19th century only the au diphthong was centralized. This is a sometimes mocked stereotype of Canadian speech. In the 20th century, but prior to Labov’s visits, successive cohorts of adolescents had each tended to overshoot the mark, with a result that the first vowel of the ai diphthong was centralized as well. This is the sound change to which the title of his paper refers as having a social motivation.
That people tend to speak like those with whom they most speak is not a finding, it is a commonplace. Modeling Labov’s actual finding would be of value, but rather challenging.
