Re: Fitting data to models
[Martin Taylor 2005.10.11.17.18]
[From Rick Marken (2005.08.08.0820)]
Bill Powers (2005.08.07.1924 MDT)–
Rick Marken (2005.08.07.1210) –
Two other quick observations on this topic.
- The results one gets when trying to fit models to data
depends
not only on the model(s) but also on the quality of the
data.
In Martin’s experiments, he had little to say about how the
experiments would be conducted.
I know. I didn’t mean to appear to be criticizing the quality of
Martin’s
data. All I mean is that, in general, for any data, the goodness of
fit you
can get is limited, to some (largely unknown) degree by random
variations
(like the mouse slips I mentioned). This random variation may be quite
large
(as it is in the typical psychology experiment, where models are
considered
“good” if they pick up 30% of the variance) or quite small
(as it is in
control experiments, where we can regularly pick up 99% of the
variance in
some variables).
Quite so. And I take your earlier point: " When I start
finding myself trying more and more subtle strategies to improve the
fit of a model to data, I realize that I am acting like an obsessive
gambler: I see myself thinking “I bet I can find a way to set the
parameters so that I can get the average RMS error over subjects down
from 18 to 15 cm, beating out the alternative model”
This is a problem of which I’m well aware. We all get caught in
it sometimes. I hope I’m not in that position right now.
I am in the position of having difficult data out of which
something interesting may come. It’s noisy for two reasons, perhaps
more. The two reasons are (1) the inconsistency inherent in having
sleepy subjects doing a task that is not of particular concern to
them, and (2) the inconsistency inherent finding the best
multi-parameter fit of a model when the form of the fitting function
is unknown and one has to use a randomized approach to the optimum
(the genetic algorithm outperforms e-coli, but it is still far from
guaranteed to find the best fitting parameter set for a given
model).
Given those two inherent reasons for noise in the data, I’m not
going to insist that results apply uniformly to every subject.
(Anyway, I believe that to be a wrong expectation in most
circumstance, but I won’t argue that point here. People can be
different, and that’s all I need to point out).
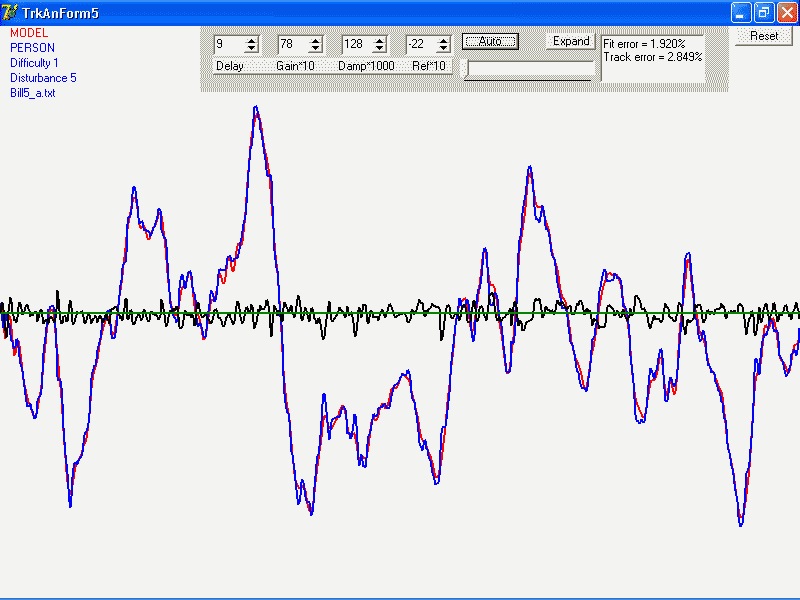
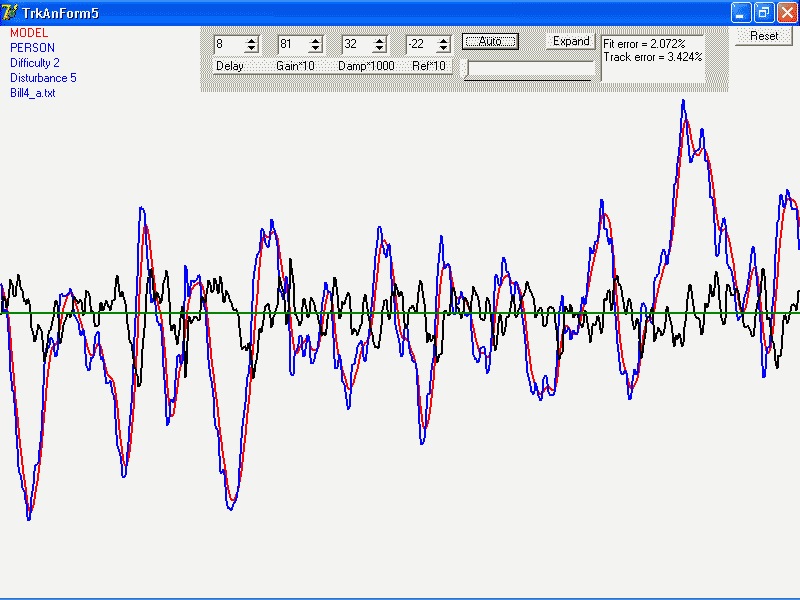
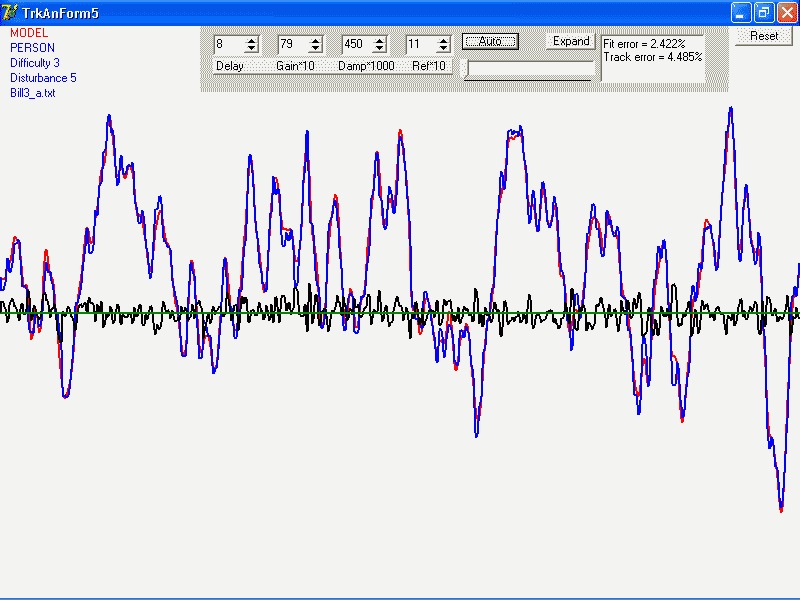
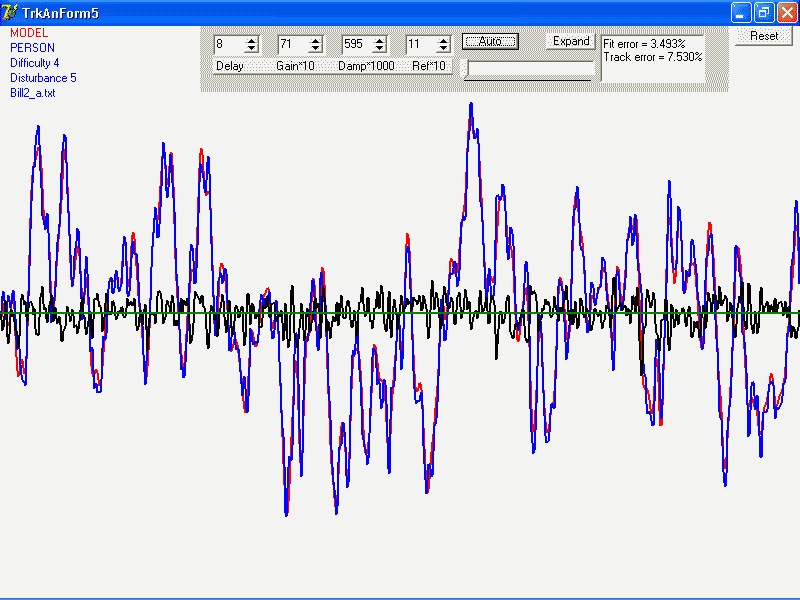
Now for the item of interest I discovered today. It’s embodied in
the graph I both attach to and embed in this message.
As you may remember, I’ve been doing a long-running program of
fitting two different models to some 1300 pursuit tracking runs, 42
from each of 31 subjects (there were 32, but one got sick and didn’t
finish the experiment. The data from that subject are totally
ignored). There were two kinds of tracking, one in which the target
was a two-digit number and the subject controlled another two-digit
number, the other in which the target was a line length and the
subject controlled the length of a different line. For each type,
there were three levels of complexity: “Easy”, in which the
subject equated the controlled value to the displayed target value;
“Medium”, in which the subject was asked to equate the
controlled value to the displayed target plus or minus a quantity that
was fixed for the length of the run; and “Hard”, in which
the subject equated the controlled value to the sum or difference of
the displayed target and another value that changed more slowly during
the run.
There was no attempt to balance the number of male and female
subjects in the study. Of the 31, 14 were male, and 17 female.
As I said, I’ve been fitting two models. At the CSG meeting I
called them “Model A” and “Model B”. In the graph,
they are “17o” and 18a" (which perhaps gives you an
idea of how many models have been tested in all). Both provide
reasonable fits to many of the tracks. Recently, I’ve been comparing
them track-by-track in two ways, the relative goodness of fit, and
simply which one gives the better fit.
When I looked at the first batch of subjects, it seemed quite
clear that the “17o” model was more likely to give the
better fit, but that this preference declined sharply for the
“Hard” conditions, both number and line-length (I call those
“numeric” and “graphic”). When I looked at the
second half of the subjects, this pattern was not there. I figured
that there might be something different about the subjects and their
ways of looking at the world, so I went back to the experiment logs to
see if I could find anything.
An obvious thing to check is gender. It turned out that most of
the subjects in the first batch were male, and most in the second
batch were female. So I looked at the pattern for each subject
individually, making one graph with 14 lines on it for all the male
subjects and one with 17 lines for all the female subjects. The two
graphs were quite different. One male subject had a pattern that would
have fitted better in the female group, and two females had patterns
that would have fitted better in the male group.
The next thing, which I finished a few minutes ago, was to take
the male and female probabilities that model 17o provided a better fit
than model 18a for each of the six experimental conditions. These are
averaged across all male and across all female subjects. I show them
the numeric and for graphic conditions separately. There seems to be a
clear difference between the sexes in how they deal with the
complexity of the task, and that difference is consistent between
number tracking and line-length tracking.
The main difference betweenthe models is that 17o compares the
(delayed) perception of the target value with the current value, and
uses that to set the reference for the difference between a (delayed)
perception of target velocity and the current cursor velocity, whereas
18a uses the (delayed) perception of the target velocity and the
(delayed) perception of the target position to produce a current error
value which is used to set a reference for cursor velocity.
I’m trying to think of a model I can parameterize that would
contain elements of these two models and that is psychologically
plausible, with a view to seeing if I can find a parametric shift that
makes sense and that suggests a link with other mental characteristics
differentiated by sex. But I’m off to a NATO meeting on Friday, and
won’t get to it until November. I thought I should give you this minor
progress report before I left.
Martin
![]()
ModelFits_Gender.pdf (16.3 KB)
ModelFits_Gender.pdf (16.3 KB)