In linguistics, the Test is typically performed by repeating an experimental utterance while making a substitution for some identified part of it.
The locus classicus for the methodology of descriptive linguistics is Methods in Structural Linguistics. By these methods, language perceptions are identified and tested to verify that they are just those perceptions, control of which constitutes the given language. By these methods, the controlled variables are paired with written or iconic representations by means of which the linguist describes the language under consideration and by which another person can learn it, given appropriate prior training in the conventions of linguistics and in relevant physiological, acoustic, and socio-cultural phenomena.
I wrote an early exposition of the kinds of variables that constitute languages as my contribution to the Festschrift for Bill powers. A more recent exposition begins on p. 378 of my chapter in LCS IV.
It is often the case that control of a given variable appears to be poor. In general, each variable is controlled by setting references for a plurality of lower-level perceptions, not all of which need contribute to that input function for the higher level variable to be perceived and controlled. This ‘redundancy’ is functionally important in a noisy environment. When other inputs suffice for the higher level variable to be perceived and controlled, the higher-level system may reduce the strength of the reference signal for the given variable–the specification of how much of that variable must be perceived.
To illustrate, consider the pronunciation of the word to. Pronounced with high gain, as in he wandered to and fro, there is a clear burst of high-pitch sound after the t, the dorsum of the tongue is lifted toward the velum with the lips protruded, producing a syllable homophonous with too and two, having vowel formants at about 320 Hz and 800 Hz (for a typical man; all frequency ranges are shifted higher by the shorter vocal tract length of women and children). In He wanted to go the release of the t is as audible, the tongue is lowered and the lips in a lax, neutral position, producing first and second formants centered at something like 600 Hz and 1200 Hz. In I want to go, the word to may be pronounced the first way in very emphatic speech, may be reduced to the second pronunciation in less emphatic speech, and typically is even further reduced to what we can write conventionally as “I wanna go”, where t is entirely omitted after n and the tongue is in a lax central position producing formants centered at something like 500 Hz and 1300 Hz. This is reduction of gain rather than loss of control.
A second reason that control of a given language variable commonly appears to be poor is conflict between control of one variable and control, either concurrent or sequentially, of another. Limiting ourselves still to variables controlled for pronunciation of words, tongue twisters and spoonerisms are readily accessible examples of the latter. The tongue and other articulators are in position to produce acoustic effect A but must be moved to different positions as means of controlling acoustic effect B. We cannot ascribe these mispronunciations, nor their patterned and predictable character, to lag time changing the lower-level referents, because the same people can and do pronounce them correctly, often immediately after. The tongue cannot move instantly from one reference position to another. Physical properties of the oral cavity and of the musculature are in effect disturbance to control of B when the tongue starts from control of A. Furthermore, if B is controlled with equal or higher gain that can interfere with control of the prior segment A in an anticipatory way. (There is a very large literature on all of this.)
Pronunciation is controlled concurrently in two sensory modalities. We control the sound, yes, but we do so by adjusting the reference values for how it ‘feels’ to produce the given sound. We cannot correct the sound in real time. By the time it is audible it’s too late, the only way to change it is by repeating the utterance.
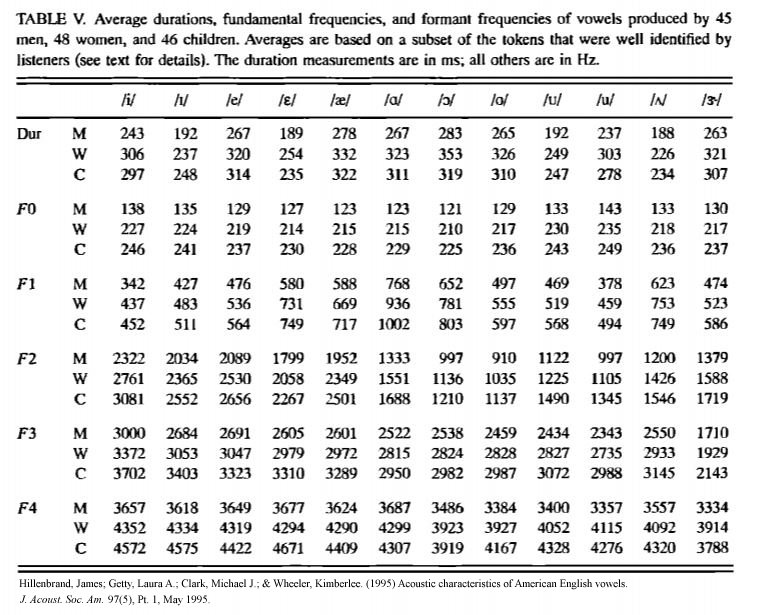
On pp. 383-386 of my chapter in LCS IV is a diagram for a PCT account of experimental work done by Katseff et al. in the phonology lab at UC Berkeley. I did not perform the test in that instance, not having the specialized hardware on loan from the Otolarangeology Department at USF as they did, but I did propose it on CSGnet in 1991-1992. They disturbed the acoustic result of pronouncing head so that it sounded to them more like hid. They resisted the disturbance by pronouncing it more like had. (See the formant data for ı, ɛ, æ in the table above.)
However, subjects did not completely resist the disturbance because the same higher-level system controlling a perception of head receives input not only from the acoustic control loop but also from the articulatory control loop. (You can verify this for yourself by reading this sentence while holding your breath, silently moving your lips and tongue. You may find yourself articulating especially ‘emphatically’–something the higher-level systems do e.g. in a noisy environment.) As the acoustic control loop changes the references toward had, the articulatory input is a disturbance to perceiving head. In the resulting conflict, neither loop was able to control completely. Control of articulation is means of controlling the sound, and other than in this extremely artificial experimental situation the two control loops do not come into conflict. Katseff et al. came to the same conclusion, that control of articulation ‘somehow’ interfered so that the disturbance of the sound was not completely ‘compensated’, but they did not have HPCT to explain why this was so and how it works.
