[Bruce Nevin 2018-05-20_20:25:08 ET]
The output from the vocabulary website through a computer’s speaker was re-recorded by a student on their cellphone. Changes in the sound spectrum are made it ambiguous.
Here are three spectrogram images from the NYT page:
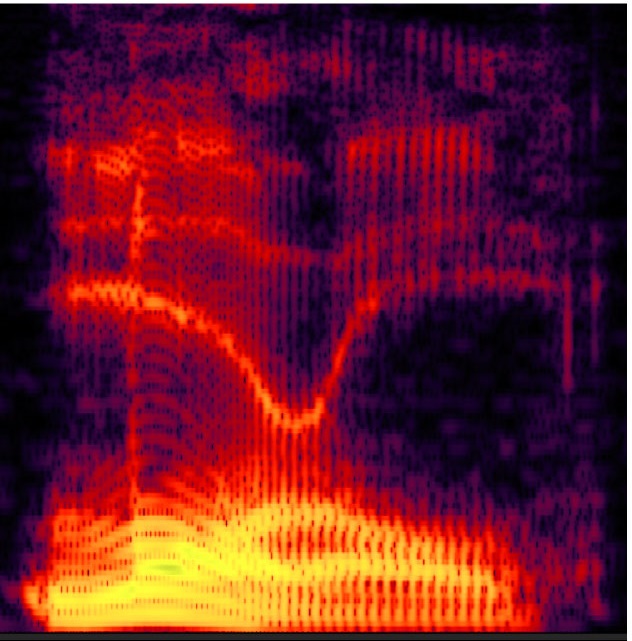
Laurel (presumably a relatively clean output from the vocabulary website)
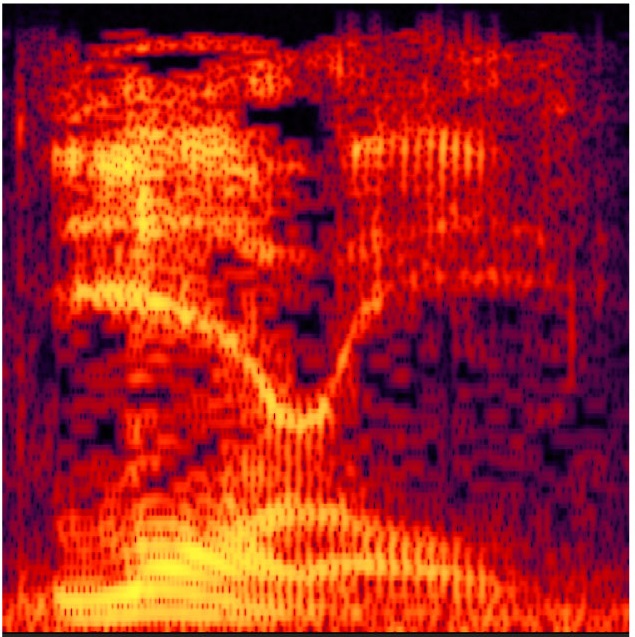
The ambiguous dub made on a cellphone held up to a computer speakerÂ
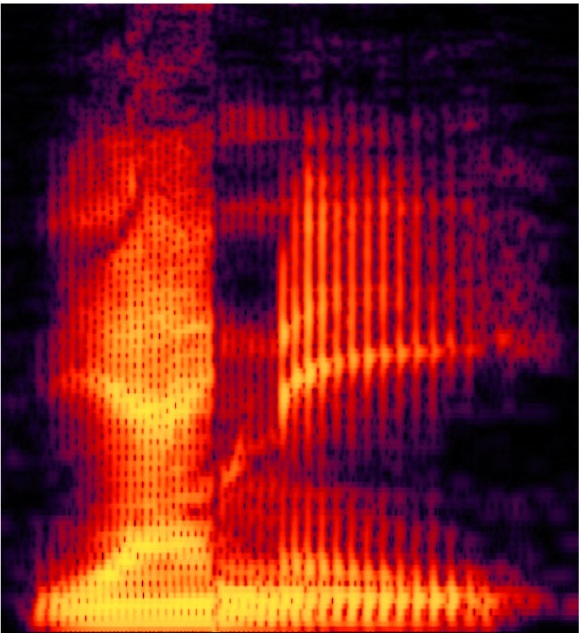
The NYT approximation of “yanny,” made by combining parts of two words on the vocabulary website, âYangtzeâ? and âuncanny.â?Â
I can’t vouch for how well they clipped and matched the “ya” of “Yangtze” and the “anny” of “uncanny.” But you can clearly see that in fact in the dub you cannot so clearly see the features that are visible in either the image above it or the image below it. This is a visual representation of ambiguity in the auditory signal.Â
Grounding this in our theory, as I understand its application to speech perception: given the sounds represented by the first image, perceptual input functions for initial L fire much more strongly than those for initial Y, and given the sounds represented by the third image, conversely, perceptual input functions for initial Y fire much more strongly than those for initial L; and so on for the medial R vs. N and for the vowels. But given the muddied signal represented by the second image, both fire.Â
In “Laurel”, the intensity of sound energy (pulsation of the air) is relatively attenuated (more damped)Â at higher frequencies and relatively stronger at lower frequencies, and in “Yanny” the converse is true, lower frequencies are weaker and higher frequencies stronger. Differences in capacity for perceiving higher and lower frequencies play a role. Most people lose ability to hear higher frequencies as they age. In some, the right ear is more affected; I speculate e.g. about men leaning into their work with power tools held in their right hand. However that may be, you may find interesting subjective differences in your own perceptions with the NYT slider demo, listening first with one ear and then with the other.
I hear a different consonant when I push the slider all the way over to the right, neither the L of laurel nor the Y of yanny, and I hear a different consonant in the middle, neither the R of laurel nor the N of yanny. What do you hear there?Â
Each vertical striation corresponds to one pulse of the vocal folds, but the articulated movement of the vocal folds does not produce a pure sine wave. Like a square wave, it produces a fundamental frequency (the pitch) and many harmonics. Height on the vertical dimension corresponds to higher and lower frequencies. The fundamental frequency (pitch) is at the bottom, and multiplies of that (its harmonics) are progressively higher. The oral cavity damps some frequencies and resonates with others, and which are damped and which are resonated is determined by the changing shape created by the jaw, tongue, and lips. So we move our jaw, tongue, and lips (and other articulators) to control the changing relative strengths of harmonics of the fundamental frequency as means of hearing ourselves speak.
There’s a nice tutorial on how to read sound spectrograms here:
https://home.cc.umanitoba.ca/~robh/howto.html
···
On Sun, May 20, 2018 at 4:55 PM, Richard Marken csgnet@lists.illinois.edu wrote:
[Rick Marken 2018-05-20_13:51:59]
Bruce Abbott (2018.05.19.2038 EDT)]
Â
BA: Here in the States there has been a lot of attention given to an online dictionary audio clip that pronounces the word âlaurel.â? About half of those listening to the clip hear the speaker say âlaurelâ? and the other half hears âyanni.â? Apparently, what one perceives depends on how well you can hear certain frequencies of the auditory spectrum, the frequency spectrum of the device that produces the sound, and perhaps the background noises that may be present in the environment of the listener. This provides an excellent example of how different individuals may perceive the âsameâ? environmental input differently.
RM: I was going to agree but then I did the demo you sent and I’m pretty sure that different environmental inputs are the basis of the different words heard in this “illusion”. Â
 BA: You can try an demo that allows you to change the spectrum so that you can hear either word here:
https://www.nytimes.com/interactive/2018/05/16/upshot/audio-clip-yanny-laurel-debate.html
RM: I presume that as I move the pointer from the center to the left, toward “Laurel”, or right, toward “Yanny”, I am moving toward a low or high pass filtered version of the sound sample, respectively. I am now able to adjust the pointer so that the filtering allows me to hear both “Laurel” and “Yanny” at the same time. I presume this is because the acoustic (environmental) basis for both perceptions is present in the waveform and so both can be perceived simultaneously when I adjust the pointer so that I am listening to a fairly wide band version of the sound sample. The spectrograms suggest that this is the case.Â
RM: So the “Laurel/Yanny” illusion is not really a demonstration of the same environmental input being perceived differently. I think a better demonstration of that is my “What is size” demo (http://www.mindreadings.com/ControlDemo/Size.html) where the same environmental variables (the lines on the computer screen) can be perceived as the perimeter or area of a rectangle. But it is interesting that I was able to control for hearing both Laurel and Yanni at the same time by adjusting the filtering so that it was slightly toward low pass. I think that’s because we are more sensitive to higher than lower frequencies.Â
BestÂ
Rick
–
Richard S. MarkenÂ
"Perfection is achieved not when you have nothing more to add, but when you
have nothing left to take away.â?
                --Antoine de Saint-Exupery