[Martin Taylor 2017.10.11.10.21]
[From Rupert Young (2017.10.11 10.00)]
(Rick Marken (2017.10.09.0915)]Yes. Which was what I said.
The following is a tentative suggestion about simulating the
development of novel perceptions of an environment, in an attempt to
answer Rupert’s question.
Remember that the Arm2 demo operates in an external environment
devoid of content. The Little Man operates in an external
environment that contains a single moving object. Neither
environment has anything for the “organism” to learn about, so they
can’t be used as examples for the development of novel perceptions.
But their principles can.
Let's imagine something along the lines of a complement of the Arm 2
demo, or rather, a possible series of them, which I call Baby0,
Baby1, …, BabyN. Each builds on its predecessor. Baby0 starts with
an almost trivially simple environment and a bunch of pseudo-neurons
that could arrange themselves into the form of control loops with
perceptual functions. The question is whether Baby0 can develop two
perceptual functions that will allow it to stabilize two variables
in its environment.
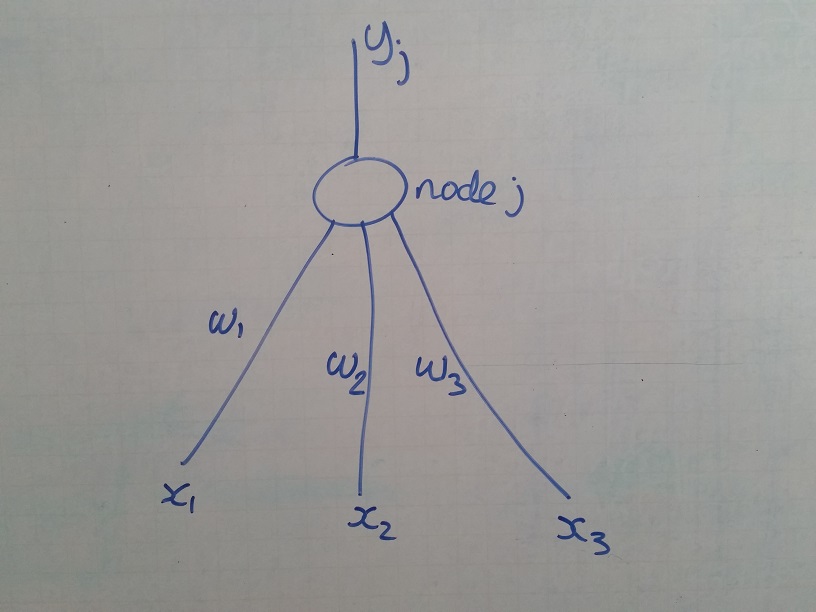
To help describe BabyN and its environment, I will use some naming
conventions. Variables in the environment will be Vn, as in V1,
V2,… Environmental variables are individually influenced by
disturbance variables Dn, in the sense that Vj is influenced by Dj.
The Dn are driven by the experimenter. Sensory variables, reported
to the interior of BabyN will be S1, S2, … It may be true, but
more often will not be true, that an S variable corresponds directly
to a V variable. Perceptual variables will be Pn, reference
variables Rn, error variables En, output variables On, and Actuator
variables (analogous to muscle tensions or joint angles) An. As with
the sensor variables, an actuator variable may, but usually will
not, be associated directly with an environment variable.
One more acronym I will use is "PNn" for "Pseudo-neuron number n". A
PN has a number of inputs, performs some function on them, (often a
simple addition) and produces an output. PNn output is connected to
one of the PNm inputs by link Lnm, which has a real number weight
and possibly a defined delay (but we will worry about that much
later). In principle, any PN output may be linked as an input to any
or all other PNs. In the early BabyN series, however, PNs come in
families that have specialized linkage possibilities. The
experimental (or demo) question for any of the BabyNs is whether,
under the initial conditions specified, it will reorganize to
produce perceptual functions that enable it to live effectively in
its particular environment. I describe “live effectively” when I
come to “intrinsic variables”.
A "newborn" BabyN may have some control units already constructed,
but it also has (or may create) uncommitted PNs that might form new
control units. Baby0 has nothing pre-constructed, but uncommitted
PNs come in several different types or flavours, perceptual,
comparator, and output (two sub-types). A perceptual PN (pPN) can
accept input from a Sensor or from the output of a pPN. An output PN
(oPN) can accept input from the output of a comparator PN (cPN), and
produces output that can be linked to any number of oPNs or As. A
cPN can accept input from oPNs and pPNs and sends output to oPNs.
oPNs are special in another way. They come in two subtypes, one that
acts like a simple multiplier with a gain subject to reorganization,
while oPNs of the other type act as leaky integrators, and their
gain rate and leak rate are subject to reorganization.
The classification of PNs into different types reduces computational
complexity greatly if there are large numbers of S and A variables
and the environment is complicated. It would be perfectly possible
to describe the whole experiment as using PNs with no type
distinction, and I did so in an early draft of this message, but a
few back-of-the-envelope calculations suggested that the
reorganization time would very quickly get out of hand, even using
the e-coli method used by Powers to solve that same problem.
The influence of actuators on environmental variables is fixed for
the duration of any experimental or demo run, as is the influence of
the environmental variables on the sensors. The disturbances vary at
the experimenter’s whim.
Time must be considered. As this is a computer-based simulation,
time must be sampled, and one time unit could be the time between
samples. There must also be a delay associated with every link, but
these delays might be much shorter than a sample time, and therefore
could be taken as zero. The total loop delay, however, cannot be
taken to be zero. To ensure this, I will arbitrarily say that it
takes at least one sample time for a change in the output of an
actuator to be felt at a V environmental variable. Integration rates
and leak rates for the leaky integrator kind of output function can
be measured in rates per sample without loss of generality.
One further thing is needed, intrinsic variables to set the rate of
reorganization. Reinforcement Learning has a significant problem in
the “assignment of credit”, which different proposals finesse in
different ways. PCT has less of a problem in this, because each
control loop is responsible for best controlling its own perceptual
variable. The better the control, the more stable are all the
variables in the loop. I propose to use this fact as a local
intrinsic variable, to go along with the global intrinsic variable
of minimizing overall error. Reinforcement rate is the probability
of an e-coli move during any time sample.
Even though this is a simulation in which the intrinsic variable is
quite arbitrary, we can take a cue from real life. The big problem
with the human brain is how to dissipate the heat of neural
operations, primarily caused by neural firing. Our simulated neurons
(our PNs) don’t fire. They produce larger and smaller “neural
currents”, which can be positive or negative. Since electrical power
is I2R or V2 /R, one index of equivalent energy
usage of a PN might be the variance of its output. But then “R”,
resistance, also enters the formula. R must be related to link
weights. Indeed, what reorganization will do is change link weights,
so they are critical to the intrinsic variable we seek.
In a real brain, the firing rate of a neuron is not (so fas as I
know) influenced by how many synapses are reached by each impulse.
If it were an actual current, this would not be true. But a firing
is actually a voltage spike, not a blast of current. The Powers
“neural current” is perhaps better seen as an average voltage rather
than a summed current. Taking this view, in our BabyN, resistance
would be the inverse of link weight, so the momentary power of a PN
would be represented by (output2 )/(sum of output link
weights to other units). The energy generated as heat over a time t
would be t*(output variance)/(sum of link weights).
Energy cannot be dissipated instantaneously. It leaks away at a rate
proportionate to the temperature difference between the hot and cold
regions. In BabyN, we can simplify this and use it in reverse, to
indicate how hot the PN would be after some period of activity. The
temperature is proportional to the integrated energy produced by
firings, less that dissipated into the environment. It is therefore
the output of a leaky integrator that has input rate as above and
leak rate proportional to the current temperature difference between
the PN and the surroundings.
What are the surroundings of a PN? There are two parts, an outer
“cold” universe that we can take to be at zero temperature, and
nearby PNs. Since we have no self-organized way to localize a PN, we
must be arbitrary. I propose that all PNs of the same type (pPN,
cPN, and oPN, not distinguishing the oPN subtypes) should be the
neighbours of a PN. The resulting “cold sink” temperature would then
be somewhere between the average temperature of the neighbours and
zero. Perhaps half the average temperature of the neighbours might
be a simple starting point.
This temperature will be our intrinsic variable. If a PN gets too
cold or too hot, it will lose efficiency and reduce its output for
any given input. On the other hand, in a global sense, the cooler
the entire ensemble is, the less difficult it is to configure the
brain (in an evolutionary sense) to fit in a reasonable size of
skull. This suggests that there should also be a global intrinsic
variable for average temperature, with some reference value. For
simplicity, we might start by suggesting that the global temperature
optimum would be the same as for the individual PNs (a value
controlled by the experimenter in the early members of the BabyN
series, but possibly self-optimized in more complex versions).
The tension between the global and the many local intrinsic
variables should lead to a steady operating temperature with a
minimum number of PNs contributing to the work, because the more
operating PNs there are, the more heat there is to dissipate and the
hotter the ensemble becomes.
Reorganization: Each BabyN has variable input through its sensors.
These induce variation in all the PNs that are initially randomly
interconnected, generating “pseudo-heat”, which makes them all get
hot, some more than others. Each PN uses local e-coli
reorganization, treating the in- and out-link weights as coordinates
in a local space. (There must be an e-coli administrator hidden in
the genetic structure of the organism, but I won’t attempt to
suggest how it got there. I just assume it exists, as did Powers).
The global intrinsic variable also induces its own e-coli
reorganization, using all the link weights. The interactions between
the local and global e-coli effects will skew the apparent
directions in both when seen by an external analyst, but the local
and global effects do not interfere with each other, nor do they
operate at the same rate. A particular PN might be near its optimum
“temperature” while the ensemble is much hotter than the global
optimum. Imagine that we had just two links to work with. Locally,
the last step was, say, {1,2} and performance improved, so the next
step will again be in the same direction {1,2}. But global
reorganization says that the next step will be in the direction
{-.5,1}. The resulting actual next step will be {0.5,3} as seen by
an external analyst, but will be {1, 2} and {-.5, 1} as seen by the
local and global e-coli administrators (who are hidden in the
structure of the BabyN series).
As written above, I feel there is too much arbitrariness in the
detail, and perhaps a simpler global-local algorithm might be used
to determine changes in the global and local intrinsic variables. In
more complex organisms than are anticipated in the BabyN series, the
organism would have to find food in order to sustain its energy
dissipation, a topic that is totally ignored here. But note that
warm-blooded animals and cold-blooded animals alike must maintain
their body temperature within fairly strict limits or cease
effectively controlling, so treating temperature as an important
intrinsic variable both locally and globally seems a very natural
thing to do.
···
RY: Sure. But, as far as I cansee, it is mostly conceptual. The only formal
definition I’m aware of is Bill’s arm reorg example in
LCS3, of gradual weight adjustments of output links,
which improves control performance. I don’t see
anything on how perceptual functions are learned. Or
how memory (which is learning) fits into
reorganisation.
RM: The arm reorg example in LCS3 seems to be morethan conceptual; it actually works.