[Martin Taylor 2009.01.04.15.32]
Following on from …
Martin
Taylor 2009.01.03.22.54]
Which should be understood before reading the new material. I repeat
some of it…
All probabilities are subjective in the sense that they depend on
the background knowledge of the observer. The background knowledge may
include models, records of previous occurrences of the “probabilistic”
matter, pure intuition, faith, and anything else you can think of.
“Frequentist” probability, on which significance statistics are based,
takes into account only records of previous occurrences (but see below
for a problem with even this).All probabilities are conditional. That’s part of the background
knowledge that you bring to bear. In the “frequentist” view of
probability, you look at N situations, and say that on M of them the
event E happened, so the probability of event E happening the next time
is M/N. But that’s not legitimate, You should at the very least say
“conditional on the N situations all having the same characteristics
insofar as event E is concerned, and on the next occurrence of the
situation it will also have those characteristics.” In physical fact,
no two of the N situations had all the same characteristics. At the
very least, the universe had a different age when each occurred.…
What
you can say about the “White Swan” problem is that if the conditions
remain the same, the likelihood that the next swan you see will be
white increases the more swans you have seen without seeing a non-white
one. Let’s consider some hypotheses about that. Say we have been
observing swans and they have all been white. We know little enough
about the background of these swans that we are prepared to say the
conditions will be considered to be “the same” the next time we see a
swan, any swan. The hypotheses we will consider areH1: No swans are white.
H2: Half of all swans are white
H3: 75% of all swans are white
H4: All swans are white.
That’s what we did in Episode 1. We found that if we had no initial
preconceptions about the proportion of swans that are white, we could
find posterior probabilities for the four hypotheses given that we had
seen 10 swans and all of them were white. These four hypotheses were
samples from an infinite set of hypotheses of the same type, the
hypotheses differing only in the value of a single parameter:
Hx: The proportion of swans that are white is x (0 <= x <= 1.0).
In other words, given that we have seen a bunch of swans (we will keep
10 as the example), what is the (subjective) likelihood of the
hypothesis? We will see that in this case we can’t specify a subjective
probability for any single hypothesis (all of them must be
infinitesimal), but we can find a total probability for hypotheses
within a range of values of x.
from Episode 1, we had:
After
seeing 10 swans which were all white, we can compute the likelihoods
from the initial formula rather than recomputing new prior
probabilities, but we can simplify by ignoring p(D) because it always
falls out from the comparisons. D in this case is the observation of 10
swans, not just of the tenth swan.L(H1|D) = 0.25 * 0 = 0
L(H2|D) = 0.25 * (0.5)^10 = .0002
L(H3|D) = 0.25 * (0.75)^10 = .014
L(H4|D) = 0.25 * 1 = 0.25
Normalizing so that the probabilities sum to 1.0, the posterior
probabilities arep(H1|D) = 0
p(H2|D) = 0.0009
p(H3|D) = 0.053
p(H4|D) = 0.947
By this point, the initial prior distribution has become almost
irrelevant.
This is an important point, because most critiques of Bayesian analysis
centre on the difficulty of setting up “correct” prior probabilities.
It is, in principle, impossible to set up “correct” prior
probabilities, because they depend on what each person believes or
assumes before making the observations.
I am not sure, but I think I first appreciated the way data overwhelm
the “prior problem” when I read Satosi Watanabe’s magnificent “Knowing
and Guessing: A formal and quantitative study” (Wiley, 1969). If you
haven’t read that book, I highly recommend it. For me it was one of
very few books that have seriously changed my way of thinking (others?
B:CP, of course, W.R.Garner “Uncertainty and Structure as Psychological
Constructs”, Wiley 1962, which I read in manuscript while I was
Garner’s student, Norbert Wiener’s “Cybernetics” – not “The Human Use
of human Beings”, and Von Neumann and Morgenstern’s “Theory of Games”
which I read when on a transcontinental train trip as a member of a
cricket team going to an Inteprovincial tournament in Vancouver. There
were probably others, but those are the ones I remember best).
Back to the chase. Now, for any value of x, the hypothesized likelihood
that a random swan (or equivalently in this case, the very next swan)
will be white, we can say that L(Hx|D) = x^10. Here is a graph of x^10
for x between 0 and 1.0. The curve shows the relative likelihood of the
hypotheses shown on the x-axis. To get the posterior probability
distribution, one must multiply one’s prior probability distribution
point by point with the values on this curve.
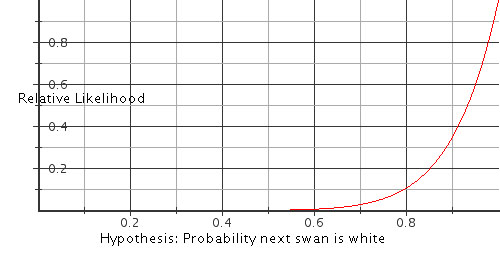
This is a graph of the relative likelihoods of all the infinite number
of possible hypotheses, scaled so that the maximum value is unity. Any
other scaling would be permissible, since all that matters is the
amount by which one hypothesis is more credible than another. For
example, after seeing these 10 white swans, the hypothesis that 95% of
all swans are white is 1.71 times as likely as that 90% are white, and
0.6 times as likely as that all swans are white.
After getting the data that these first 10 swans were white, you can
adjust your subjective probability that the next swan will be white by
multiplying your prior probability for any given hypothesis by the
value on this curve. As we did in part 1, you then must scale so that
the integral of the resulting curve is 1.0 (or the sum, if you had a
finite prior probability for only a finite set of initial hypotheses,
rather than the continuum implied by the likelihood curve).
Remember that these likelihoods are all subjective, and are all
conditioned on certain presumptions, notably that the swans we have
seen are representative of all swans, and that we are as likely to have
seen any one individual swan as any other. If you have other
conditionals, your likelihoods might change. For example, you might
have an initial assumption that all swans in a flock are the same
colour, but the colour changes from flock to flock, and you might have
come to believe that all the swans you have seen so far belong to the
same flock. Then observing 10 swans would give no more information than
observing one.
The conditionals are where all the problems arise with data sampling.
Now let’s consider what happens to our hypotheses if the eleventh swan
we see happens to be a black one. Continuing the analysis as before, we
would have:
L(Hx|D) = x^10 * (1-x)
We have ten white swans, and one black one. What conditionals are we
considering? That the black and the whites are all just swans, one as
likely as the other to come into view? That the black swan is the
forerunner of a new flock of black swans? And what hypotheses are we
asking about? “What is the probability that the next swan we see will
be white”? Or “What is the proportion of white swans among all swans?”
These considerations did not appear when all the swans we had seen were
white, but now we have a distinct difference among possible
probabilities:
-
p(next swan is white | all swans are equally likely to be seen)
-
p(next swan is white | swans fly in flocks all of the same colour)
-
p(a randomly chosen swan is white | all swans are equally likely to
be seen) -
p(a randomly chosen swan is white | swans fly in flocks all of the
same colour)
We now have the data sampling question laid out baldly. Is one swan as
good as another, or are there subpopulations distinguished by flocking
together? We have as yet no evidence one way or the other, but we can
compute the subjective probabilities of the two distinct events “the
next swan will be white” and “a randomly selected swan will be white”,
where “random” means that we have no evidence that the manner of
selecting the swan affects the result of the choice.
On the evidence at hand (ten white swans and one black one) we also
have an important question: “Does the order in which we saw the swans
matter?” Here’s why.
If we just know the numbers and not the order, there are eleven
different sequences of swan colour we might have observed, whereas if
we do know the order, there is only one. For the conditional “all swans
are equally likely to be seen”, the probabilities are similarly
affected for all the hypotheses, so the order doesn’t matter. The
probabilities for questions 1 and 3 are the same.
But if you assume (i.e. use the conditional) “swans fly in flocks all
of the same colour” the order of their arrival does matter. If the
black swan was the first you saw after you started counting, under your
assumption it must have been the last member of a black flock; if it
was the last one you counted, then under your assumption it is the
first of a black flock (meaning that you may have a rather high prior
probability that the next swan will be black, even though a flock might
have only one member, and despite the fact you have just seen 10 white
swans in a row before the black one); and if it is in the middle
somewhere, you have seen three flocks, two of them white, one black,
and the black flock has only one member. So, the likelihoods change. In
the first two cases, the likelihoods are the same as they would be if
you had seen one white and one black swan, whereas if the black swan
was in the middle of the order, the likelihoods would be as though you
had seen two white swans and one black. In all these cases, the
probabilities for questions 2 and 4 are different, and both are
different from those applicable to questions 1 and 3.
Furthermore, if you happen to want also to test hypotheses about the
distribution of flock sizes, and the black one was in the middle, then
with the conditional that swans always fly in flocks of a common
colour, you have evidence: flocks can be as small as one, and as large
as the longest sequence of whites that you have observed. The point is
that the same data can be used to adjust likelihoods on quite different
kinds of hypotheses, depending on the conditionals that you use (the
beliefs that you are willing to take as assumptions when making your
judgments).
However, let’s get back to the four different questions above, using
the conditional “all swans are equally likely to be seen”. If the
probability of seeing a white swan is hypothesized to be x, then for
consistency you must also take the probability of a non-white swan to
be 1-x. (If you don’t, then your belief level must be remapped onto the
number scale for it to be treated as “probability”). So, setting aside
the fact that there are eleven different possible orderings of where in
the sequence the black swan came, we have, as mentioned above:
L(Hx|D) = x^10 * (1-x),
and to save time later, I note that if we had 20 white swans and 2
black ones,
L(Hx|D) = x^20 * (1-x)^2
Here are the relative likelihood curves for the initial 11 observations
and for all 22, scaled so that the peak is set to 1.0.
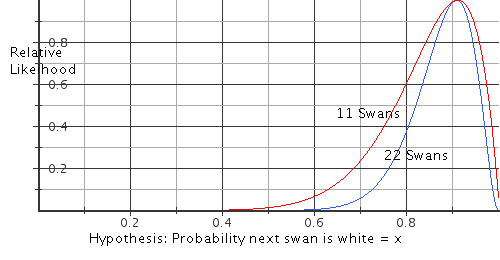
More data simply concentrates the likelihoods of the different
hypotheses. For example, if you would have bet 5 to 3 on the
probability that the next swan would be white being 0.91 rather than
0.8 after 11 swans, you would bet at a bit more than 5 to 2 after
seeing 22 swans. However, if your bet had been between hypotheses that
the probability was either 0.8 or 0.7, your appropriate odds would have
been about 12 to 5 after 11 swans and about 6 to 1 after 22 swans.
In other words, what you can do with these likelihood curves is
estimate how much the credibility of any hypothesis has changed when
compared to the credibility of any other hypothesis. They don’t tell
you what you should have as a subjective probability of any specific
hypothesis, because that depends on what other evidence you might have
from models, faith, intuition or anything else – the evidence that
gave you your prior probabilities.
But as we saw in episode 1, after you get a reasonable amount of data,
your priors don’t matter very much unless they were very strong. Given
these data on swans, you would have had to have a very compelling prior
probability that black and white swans were equally likely, in order
rationally to hold onto that view in the face of these data. People
can, of course, be irrational, and often are. These curves, however,
represent the most that anyone could get out of the data given the
conditionals on which the analysis was based. They represent the ideal
performance for these data with those conditionals.
In the handwritten seminar notes on “Bayesian Analysis, Information,
and Signal Detection”
and
, the
likelihood curves above are called the “Likelihood Gain Function”, and
the related curves of posterior probability are called the “Assessment
Function”.
Enough for this episode. I think episode 3 may deal with the sampling
problem and/or distinguishing among populations, but we shall see. I
may have a different idea by the time I get to it. For now, I’m tired
and I’m going to bed ![]()
I hope these notes are being more helpful than confusing.
Martin