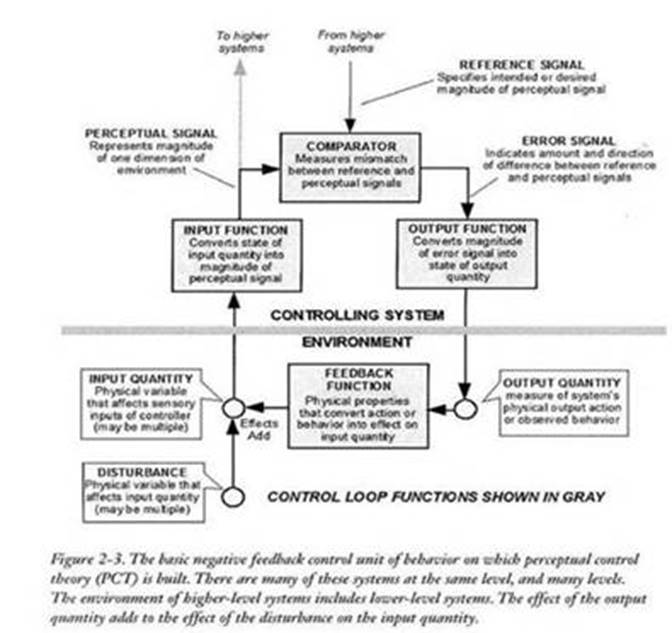
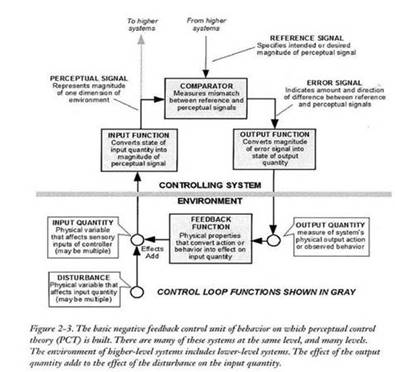
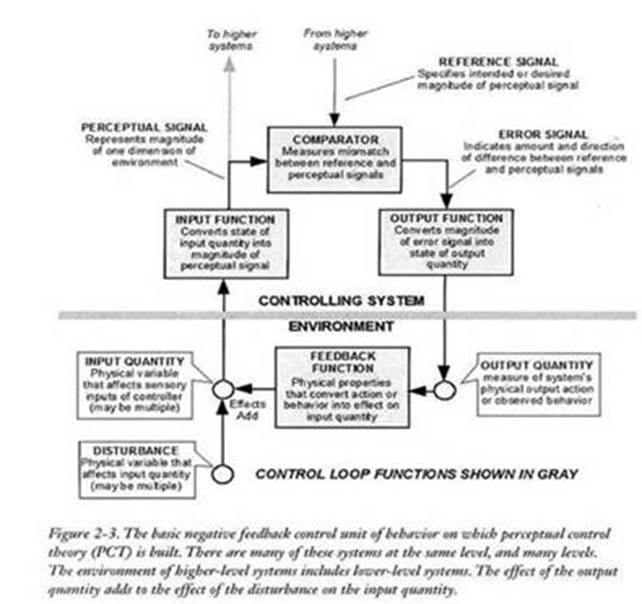
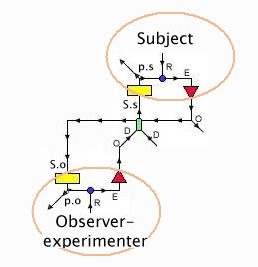
Rick
RM: But again, all this is best left for discussion at the meeting, although
it has been useful because it has convinced me that what I will talk about
at the meeting will now be how to do PCT-based research; that is, how to do
research on purpose!
HB : If you changed your mind about "behavior is control" and you'll try to
turn to real basis of Bills' "central problem" and you'd like to make some
real PCT-based reseacrh where you'll not try to prove how precise is control
done by behavior but how unprecise is mechanism of "not controlling"
external environment but yet achieving consistent result my proposal is that
you turn all your research work you've done, which is mostly of
behavioristic content into right PCT version.
The bases for your PCT research was problematic although you had and have
good ideas. I would also advise you that you remake M/S article and do it
as it should be done with right "picture" of how nervous system function.
I'm sure your feeling that you've done something good will appear. You can
be on really good way that some day you'll become the No.1 PCT researcher.
Juts turn the way of research for 180 degress.
Boris
From: Richard Marken (rsmarken@gmail.com via csgnet Mailing List)
<csgnet@lists.illinois.edu>
Sent: Tuesday, June 12, 2018 6:57 PM
To: csgnet@lists.illinois.edu
Subject: Re: The controlled quantity (q.i) is data, the perceptual signal
(p) is theory
[Rick Marken 2018-06-12_09:56:31]
[Bruce Nevin 2018-06-11_17:19:48 ET]
> there is consistent opposition to the disturbance but it is so small
that it suggests very weak control.
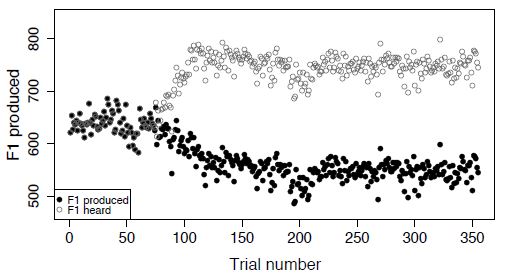
BN: I'm glad that you now accept that subjects in Katseff's experiments
resisted disturbances to F1, and that the two traces in the figures are d
and q.o, with q.i not represented.
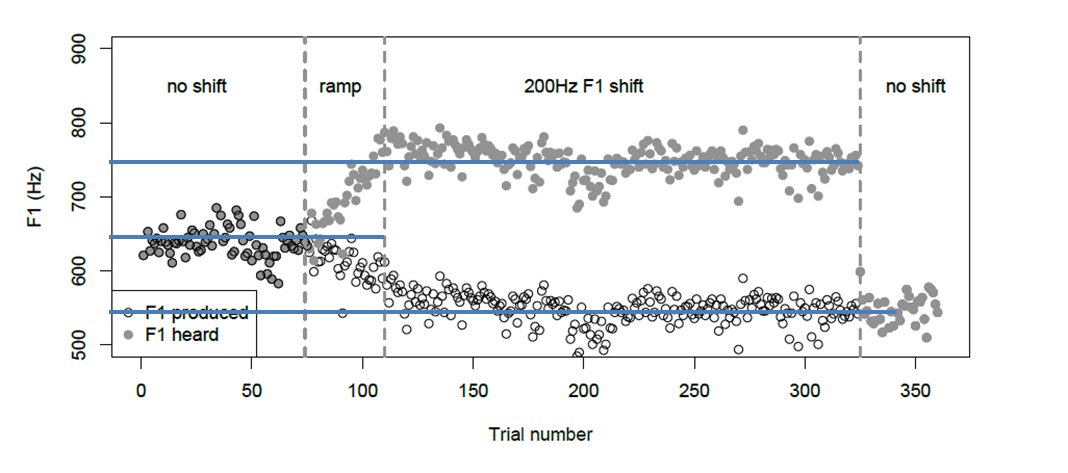
RM: I've always "accepted" that Ss resisted disturbances to F1, but I still
don't agree that the traces in the figure are d and q.o (disturbance and
output); the traces are output ("F1 produced") and hypothetical controlled
quantity ("F1 heard"). The disturbance (frequency shift) is written at the
top of the graph, as shown here:
RM: So the disturbance is "no shift", then a "ramp" up shift, then the full
"200 Hz F1 shift", and then back to "no shift". The fact that the plot of
"F1 heard" is the plot of the hypothetical controlled quantity (call it
q.i') can be gleaned from Katseff's description of that data:
The “heard�? formants...were calculated by adding the amount of formant shift
to the formant that the subject
produced.
RM: In other words, "F1 heard" is the F1 frequency produced by S (q.o) plus
the frequency shift disturbance (d); so "F1 heard" = q.o + d which is q.i',
the variable that S is presumed to be controlling.
BN: But you still don't accept that F1 is a controlled perception because
subjects only resist about 50% of the disturbance.
RM: Yes, that is far too little resistance for F1 to be considered
controlled. It is more resistance than I thought was happening -- that's why
I drew the blue lines on the graph above. The 200 Hz disturbance moves F1
from 650 Hz to 750 Hz, a 100 Hz rather than the full 200 Hz change; so
resistance is 50% effective. But that's pretty ineffective if F1 were really
a controlled variable.
BN: Katseff et al. point out that the resistance is incomplete. But the
reason that it is incomplete is not that it is uncontrolled. The reason the
resistance is incomplete, as Katseff et al. suggest in their way, is
conflict.
RM: This is because they just can't let go of the idea that control of F1 is
essential to recognition of the vowel. Conflict certainly would account for
the poor control of F1; but it doesn't account for the fact that the
subjects still say that they were hearing the intended vowel. Their varied
output was keeping some variable -- some q.i -- in the reference state. As I
said before (using the example of the coin game) the next step in PCT-based
research on vowel control would be to come up with a new hypothesis about
the acoustical variable that is controlled when people produce vowel sounds
-- a new hypothesis about the controlled quantity, q.i. This new hypothesis
-- new q.i'-- would very likely include F1 in its definition. It might even
include acoustical transitions from the contextual consonants. But jumping
to an explanation of this excellent data in terms of conflict really just
reflects a lack of understanding of what control systems control -- at least
according to PCT. They control possibly rather complex functions of physical
variables (such as temporal and spectral characteristics of the acoustical
waveform) and the focus of PCT is on trying to figure out what these
functions are.
RM: But again, all this is best left for discussion at the meeting, although
it has been useful because it has convinced me that what I will talk about
at the meeting will now be how to do PCT-based research; that is, how to do
research on purpose!
Best
Rick
The sounds that result from resisting the disturbance are result in a
perception of the intended word, head, but the actions to produce those
sounds result from control of muscle tensions and pressures (where the
margins of the tongue contact the teeth) with values that result in a
perception of another word, hid. Getting close enough to the sound of head
without getting too close to the feel of hid, the best they can do is to
resist only half of the disturbance to F1.
This may be exacerbated by the fact that the apparatus disturbed just one
formant. Correcting a disturbance to F1 requires an articulatory change in
the vertical dimension (tongue height or closeness, in the two usual ways of
describing vowel articulation). But to avoid also changing F2, this vertical
change must be done without change to the horizontal location of the
occlusion, which determines the ratio of the volume of the oral cavity in
the back of the mouth to the volume of the oral cavity in the front (between
that occlusion and the open end of the oral cavity formed by the lips). This
requires an unfamiliar articulation. What the subjects produce "sounds more
more like /ɪ/" of hid, but is not the usual articulation or sound of hid.
Just as controlling the 'feel' of pronouncing a vowel within a syllable or
word involves simultaneous control of a number of perceptions of muscle
tensions and pressure, controlling the sound of pronouncing it involves
control of several formants at once. But to recognize that word control sets
reference levels simultaneously for both F1 and F2 is not to deny that F1 is
controlled.
But yes, this will be good to discuss at the IAPCT conference at
Northwestern in October, and we an let it rest until then.
/Bruce
On Mon, Jun 11, 2018 at 1:03 PM Richard Marken <csgnet@lists.illinois.edu > <mailto:csgnet@lists.illinois.edu> > wrote:
[Rick Marken 2018-06-11_10:02:14]
[Bruce Nevin 2018-06-10_18:30:26 ET]
RM: the location of F1 is not a controlled quantity. However, the output did
slightly compensate for the disturbance (Fig. 3.10 suggests that the maximum
compensation was 1.2 %) suggesting that the center frequency of F1 is
related to a controlled quantity but is not itself a controlled quantity
BN: Sorry, this is controverted by a century of acoustic phonetics, about 65
years of machine speech recognition and synthesis, and the successes of
everyday technologies built on the basis of those achievements of science.
RM: This is probably better to discuss at the IAPCT meeting in October since
it's an interesting topic which, I believe, you are planning to give a talk
on at the meeting and right now I want to try to work on other things. But I
will suggest that you think about this research in terms of the "coin game".
The "ideal" pattern of the formants that correspond to a vowel, like those
in the cool table below that you posted, are equivalent to the initial
arrangement of the coins by S to "satisfy some condition or pattern". The
digital frequency shift is equivalent to moving one of the coins in the
pattern to see if the position of that one coin is controlled. The result of
the frequency shift to F1 was a small be consistent compensation for this
shift; this is equivalent to a displacement of the coin in the coin game
being compensated by being moved back a small amount proportional to the
size of the displacement.
RM: I say that F1 is not controlled for the same reason I would say that the
position of the coin in the coin game is not controlled; there is consistent
opposition to the disturbance but it is so small that it suggests very weak
control. At this point in the coin game E would try to come up with other
hypotheses about what it is about the coins that is being controlled. This
is not easy but at least E knows that the movement of the displaced coin is
at least weakly opposed. The next guess about the controlled variable in the
coin game would be some aspect of the coins that this only weakly disturbed
by that change in position of the disturbed coin. That's what I am
suggesting should be the next step in this research aimed at determining the
variable(s) being controlled when producing the vowel component of words.
Best
Rick
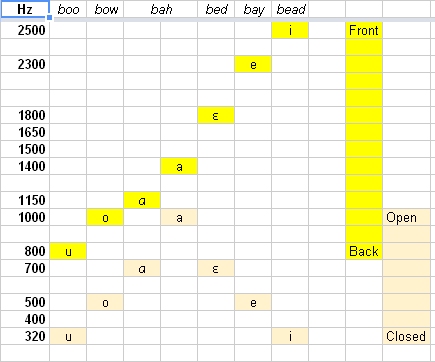
The formant values of the [æ] of "had" are between the values of [a] and
those of [ɛ], and the formant values of the [I] of "hid" are between those
of [i] and those of [e]. Of the three vowels under consideration, the [æ]
of "had" has the highest value of F1 (the [a] of "father" is higher), the
[I] of "hid" has the lowest (the [i] of "heed" is lower), and the [ɛ] of
"head" has a value of F1 intermediate between them.
Other combinations of formant frequencies distinguish vowels that occur in
other languages but do not occur in English.
Why not talk about the higher harmonics and formants? F3 and F4 are less
consequential. F3 is less important for distinguishing vowels than it is for
distinguishing consonants, as suggested by the above figure 10.2 from
Lieberman & Blumstein, but even for that F3 is not critical for
intelligibility (e.g. Agrawal A. & Wen C. Lin (1975) "Aspects of voiced
speech parameters on the intelligibility of PB words", JASA 57(1), 1975,
217-222). F3 and F4 generally track with F2, but F3 is affected by lip
spreading (say "cheese") and F4 may be affected by lip rounding.
OK, now why go through all that? A summary:
* From an examination of how the human cochlea functions, we know that
acoustic energy in the band of harmonic frequencies that we identify as a
formant (created by the oral cavity acting as a band-pass filter) causes
neural firing from hair cells in a corresponding band along the extent of
the basilar membrane (acting as a band-pass filter). This distinct neural
signal is the perception of a formant. Thus, we know that speakers perceive
formants by means of sensory apparatus exquisitely suited to represent them
as neural signals.
* At a higher level they perceive vowels as functions of these
formant-signals.
* Furthermore, from other investigations we know that speakers produce
different vowels by varying tensions in the musculature of the jaw, tongue,
lips, etc., affecting the configuration of the oral cavity (itself surely
not perceived as such) in such a way as to perceive the formants (and
vowels) that they intend to perceive.
* We also know that disturbing the frequencies of one or more formants
should result in the perception of an altered vowel. This is clearly what
happens with speech synthesis, etc.
The fact that "subjects did not notice formant shifts" (as Katseff tells us)
clearly indicates that something happened to move the disturbed formant back
toward the intended frequency in the speech signal that they heard and were
controlling in their headphones. Specifically, when the experimental
apparatus raised the frequency of F1 in what they perceived to be their own
voice transmitted through headphones, they should have heard the [æ] of
"had", but instead what they heard in their headphones was the intended [ɛ]
vowel of "head". In order to resist the disturbance, they acted so as to
lower the frequency of F1 coming out of their mouths, which (if Katseff had
noted it for us) would have approached the [I] of "hid". Because of the
headphones, the subjects did not hear the vowel of "hid" which they were
actually producing.
Katseff (and her adviser, Houde) also describe what is going on and the
purposes of their experiments in a way that clearly indicates that what the
subjects heard in their headphones was the vowel that they intended to hear,
e.g.:
Talkers compensate by opposing these feedback alterations. When vowel
formants in auditory
feedback are raised, talkers lower those formants in their speech. Likewise,
talkers
raise their vowel formants when those formants are lowered in their auditory
feedback
(Houde & Jordan, 2002; Purcell & Munhall, 2006). This general result has
been replicated
for F0 (Burnett, Freedland, Larson, & Hain, 1998) and for non-English
speakers (Jones &
Munhall, 2005).
Katseff, Shira, John F. Houde, & Keith Johnson, (2008). Partial compensation
in speech adaptation. 2008 Annual Report of the UC Berkeley Phonology Lab,
p. 448.
<http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf>
http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf
In her dissertation, Katseff says (p. 53):
When subjects do not compensate at
all (percent compensation is 0), they produce their baseline F1, and when
subjects
compensate fully (percent compensation is 100), they produce an F1 that
exactly
opposes the feedback shift.
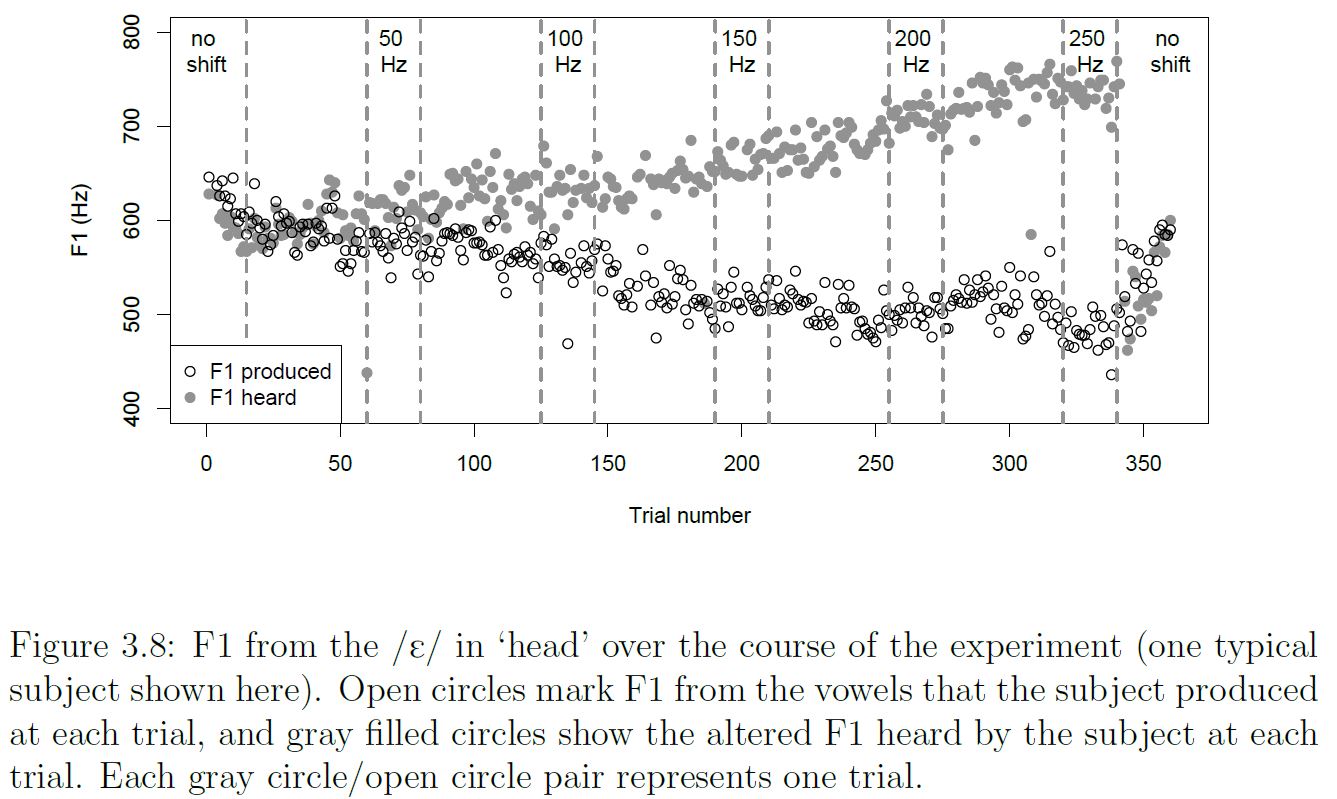
Regarding Figure 3.8 in her dissertation, previously displayed in this
thread, she writes (p. 50):
The F1 in this talker’s /ɛ/ clearly decreased for increasing formant shifts.
Likewise i
n in th
e 2008
lab report, e.g. on p 449:
As the formant values of their auditory feedback were raised, talkers
lowered the formant
values of the /ɛ/ vowels that they produced. That is, they compensated for
the change
in auditory feedback, closely mirroring the formant patterns observed in
previous formant
shift experiments. The time course of this effect for a representative
subject is illustrated
in Figure 2.
The descriptions in these (and other) paragraphs agree with the
well-established empirical fact that changing the heights of the formants
(particularly F1 and F2) changes what vowel is perceived.
But the captions below this and other figures appear to contradict this,
e.g.:
Figure 2: Change in F1 feedback and F1 production in /E/ over the course of
the experiment. Open
circles indicate the F1 values in talkers’ auditory feedback. Filled circles
indicate the F1 produced
by talkers over the course of the experiment. Each open circle/filled circle
pair represents one trial.
This is what has thrown you off. Where she says "auditory feedback" we
understand her in terms of feedback in a control loop. But she does not
understand negative feedback control loops. That's the only explanation I
have for why she thinks her term "auditory feedback" refers, not to the
signal heard by the subject in the headphones, but rather to the disturbance
that her apparatus contributes to that signal. She apparently thinks of the
disturbance as 'feedback' because it is injected into the speech signal that
the subject receives in headphones. She talks abundantly about the fact that
the 'compensation' prevents this disturbance (mis-termed 'feedback') from
materially affecting the speech signal in the headphones, but the speech
signal in the headphones is not represented in the figures.
This interpretation is confirmed by various descriptive passages that I have
quoted. I'll add this one from Katseff & Houde (2008) p. 1:
Previous work shows that subjects generally change their speech to oppose
the auditory feedback change.
For example, when F1 in auditory feedback is raised, making their /ɛ/ sound
more like an /a/, subjects
compensate by speaking with a lower F1; the vowels they produce sound more
like /ɪ/.
One of her main concerns is why resistance to the disturbance is incomplete.
These results suggest that both acoustic and sensorimotor feedback are part
of one's lexical expectation.
Because auditory feedback is altered while motor feedback is not, feedback
from these two sources can
conflict. For small shifts in auditory feedback, the amount of potential
conflict is small and the normal
motor feedback does not affect compensation. But for large shifts in
auditory feedback, the amount of
conflict is large. Abnormal acoustic feedback pushes the articulatory system
to compensate, and normal
motor feedback pushes the articulatory system to remain in its current
configuration, damping the
compensatory response.
Katseff & Houde (2008:71)
I think she's right, but she lacks the conceptual and theoretic means of PCT
to understand it clearly. I have proposed how control in two sensory
modalities come into conflict. I won't elaborate that here.
She talks about various complicating factors, e.g. in her dissertation, p.
47:
Subjects who
compensate tend to oppose the change they hear in that, if their voice
feedback has
a raised F1, they will speak with a lower F1. They will also, however,
change their
production of F2, and plausibly other components of their speech as well.
This is a
concern because calculating a subject’s change in production requires
deciding which
dimensions might register a change. If one were to look at changes in F1
production
that result from F1 feedback shifts, subjects would appear to have
compensated less
than they actually did. Understanding which dimensions actually change is
also
important for understanding processing of auditory information. Subjects who
can
produce an /E/ with a F1 that is 100Hz higher, but instead produce an /E/
with an F1
50 Hz higher and an F2 50 Hz higher, may perceive incoming vowels as a
combination
of formants rather than as individual formants. To account for compensatory
changes
in multiple formants, the experiments described in Chapters 4, 5, and 6
measure
compensation in both F1 and F2.
As noted, raising all formants can be done by shortening the vocal tract,
e.g. by lip-spreading or 'speaking with a smile'. She also broaches other
complicating factors, as for example ibid., p. 50;
It is likely that an
individual’s physiology, perception, or linguistic organization also affects
compensation
for altered auditory feedback.
But setting these considerations aside, and finally to respond the the
question implicit in the subject line of this thread, the general conclusion
for PCT is that for vowel perception q.i at the sensors at the periphery of
the nervous system is bands of excitation in regions of the basilar membrane
within the cochlea, corresponding exactly to an acoustic phoneticianʽs
perception of formants in a sound spectrogram. We could take it back to more
primitive 'aspects of the environment' = perceptions controlled by
scientists in a field that is logically and epistemically prior to acoustic
phonetics, such as acoustics as a branch of physics, or physics more
generally. I would be curious why that was thought to be necessary.
The Katseff & Houde references again are:
here again are the links to Katseff's dissertation, and to the shorter
reports and publications that I cited:
Katseff, Shira E. (2010). Linguistic constraints on compensation for altered
auditory feedback. Ph.D. Dissertation, U.C. Berkeley.
<http://linguistics.berkeley.edu/~shira/katseff_dissertation.pdf>
http://linguistics.berkeley.edu/~shira/katseff_dissertation.pdf
Katseff, Shira & John F. Houde, (2008). Compensation ?=? Mental
Representation. LabPhon11 abstracts, edited by Paul Warren, Wellington, NZ.
<http://old.labphon.org/LabPhon11/publish/LP11%20abstracts/Katseff%20and%20Houde.pdf>
labphon
Katseff, Shira, John F. Houde, & Keith Johnson, (2008). Partial compensation
in speech adaptation. 2008 Annual Report of the UC Berkeley Phonology Lab,
444-461.
<http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf>
http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf
Katseff, Shira, John F. Houde, & Keith Johnson, (2010). Auditory feedback
shifts in one formant cause multi-formant responses. Journal of the
Acoustical Society of America, 127.3:1955.
<https://www.researchgate.net/publication/42439355_Auditory_feedback_shifts_in_one_formant_cause_multi-formant_responses>
https://www.researchgate.net/publication/42439355_Auditory_feedback_shifts_in_one_formant_cause_multi-formant_responses
/Bruce
On Sat, Jun 9, 2018 at 1:12 PM Richard Marken <csgnet@lists.illinois.edu > <mailto:csgnet@lists.illinois.edu> > wrote:
[Rick Marken 2018-06-09_10:11:17]
[Bruce Nevin 2018-06-08_10:48:10 ET]
Rick Marken 2018-06-06_19:40:05 --
BN: The references I cited report a number of experiments. In the one that I
singled out, q.i is from the subject's point of view a one-syllable word
that she hears herself repeating,
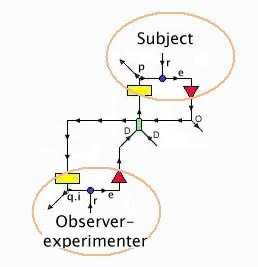
RM: It's also a controlled quantity from an observer's point of view.
BN: Yes, but the controlled quantity from Katseff's point of view as
experimenter is at a lower level of the hierarchy, the values of the
formants that constitute a vowel sound within the syllable/word.
RM: Yes, F1 was her hypothesis about one of what we would call the "lower
level" quantities controlled when producing a vowel.
BN: The apparatus shifts the lowest of these, F1. Outside this artificial
situation this could only be done by a speaker changing the shape of the
resonant cavity within their mouth. The subject resists the disturbance to
F1 by changing the shape of the resonant cavity within his mouth. From the
experimenter's point of view, listening in the environment and using
equipment that transcribes the sound produced by the subject as a sound
spectrogram, the syllable produced is different from that which he has been
asked to produce and which he in good faith intends to produce. The sound
that the subject hears in headphones, however, is close to that intended
sound. The subject's control actions counter the disturbance to F1 by
changing the shape of the resonant cavity formed in his mouth by his lips,
jaw, tongue, and velum. In the figures, the target frequency range for F1
appears on the left side, before the disturbance. As the disturbance ramps
up, the frequency range of F1 produced by the subject moves in the opposite
direction.
RM: Yes, it is great technology. Pretty advanced over "delayed feedback"!
BN: Katseff's labeling of these data points is confused, because she did not
consistently take the point of view of the subject.
RM: Actually, I believe she did take the subject's point of view. The plot
of "F1 heard" in the graph below is F1 from the point of view of the
subject. The "heard" F1 is the state over time (trials) of the hypothesized
controlled quantity, F1.
BN: The experimenter monitors two different concurrent sounds: (a) as
disturbed by the experimental apparatus, (b) as produced in the open
environment by the subject. Not represented is (c) the sound as heard by the
subject in headphones.
BN: Only the first two are represented in the figures. The caption of Figure
3.5 is confused and misleading. When she says "the altered F1 heard by the
subject" she means simply "the altered F1", i.e. the disturbance, conceived
as a 'stimulus'. The same confusion is seen in the caption for Figure 3.8:
RM: I think this is not quite right. "F1 produced" is the center frequency
of F1 spoken into the microphone; it's the frequency of F1 that enters the
digital frequency shifting system. In PCT terminology "F1 produced" is the
output variable, q.o, which is analogous to mouse position in a tracking
task. The disturbance in the graph below is a step increase in the digital
frequency shift from "no shift" to 250 Hz; so the disturbance, d, at each
point in time is written between the vertical dashed lines at the top of
the graph. "F1 heard" is "F1 produced" (q.o) plus the frequency shift
disturbance, d. So "F1 heard" -- the grey dots in the graph below -- is the
hypothesized controlled quantity, q.i = q.o + d.
RM: "F1 heard" is equivalent to the cursor position in a compensatory
tracking task where q.o = mouse position, d = the computer generated
disturbance and q.i = cursor position, which is the sum of mouse and
disturbance position. As in the tracking task, "F1 heard" is a hypothesis
about a quantity (variable) that is being controlled when a person produces
the vowel sound in "head".
BN: Notice how the value of F1 produced by the subject jumps quickly back to
the reference value of about 600 Hz as soon as the disturbance ends (the
gray circles at the top) .
RM: Yes, it's the heard value of F1 that jumps back to the pre-disturbance
level . This shows that the disturbances was nearly completely effective at
shifting the frequency of F1, indicating that the location of F1 is not a
controlled quantity. However, the output did slightly compensate for the
disturbance (Fig. 3.10 suggests that the maximum compensation was 1.2 %)
suggesting that the center frequency of F1 is related to a controlled
quantity but is not itself a controlled quantity. The next step for a PCT
researcher would be to come up with a new hypothesis about the controlled
quantity -- one that would include F1 -- and then use that nifty digital
system to introduce disturbances to this hypothesized variable to see
whether it is protected from these disturbances. This, of course, would
continue until the researcher came up with a definition of q.i that was
protected from all disturbances that should have affected it.
Best
Rick
For those who want the context, here again are the links to Katseff's
dissertation, and to the shorter reports and publications that I cited:
Katseff, Shira E. (2010). Linguistic constraints on compensation for altered
auditory feedback. Ph.D. Dissertation, U.C. Berkeley.
<http://linguistics.berkeley.edu/~shira/katseff_dissertation.pdf>
http://linguistics.berkeley.edu/~shira/katseff_dissertation.pdf
Katseff, Shira & John F. Houde, (2008). Compensation ?=? Mental
Representation. LabPhon11 abstracts, edited by Paul Warren, Wellington, NZ.
<http://old.labphon.org/LabPhon11/publish/LP11%20abstracts/Katseff%20and%20Houde.pdf>
labphon
Katseff, Shira, John F. Houde, & Keith Johnson, (2008). Partial compensation
in speech adaptation. 2008 Annual Report of the UC Berkeley Phonology Lab,
444-461.
<http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf>
http://linguistics.berkeley.edu/phonlab/documents/2008/katseff_houde_annrpt08.pdf
Katseff, Shira, John F. Houde, & Keith Johnson, (2010). Auditory feedback
shifts in one formant cause multi-formant responses. Journal of the
Acoustical Society of America, 127.3:1955.
<https://www.researchgate.net/publication/42439355_Auditory_feedback_shifts_in_one_formant_cause_multi-formant_responses>
https://www.researchgate.net/publication/42439355_Auditory_feedback_shifts_in_one_formant_cause_multi-formant_responses
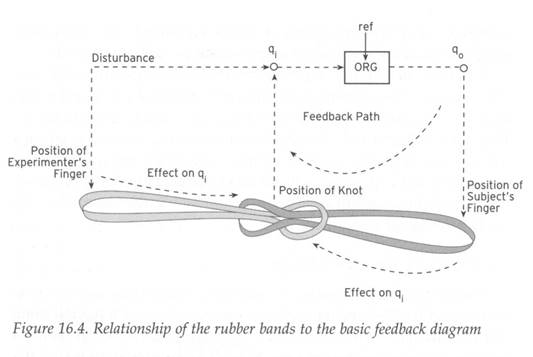
The two perceptions monitored by the experimenter are:
(a) F1 as disturbed by the experimental apparatus
(b) F1 as produced in the open environment by the subject
Unfortunately, but unsurprisingly, Katseff does not talk about q.i for the
subject:
(c) F1 as heard by the subject in headphones
However, the relationship between (a) and (b) is clearly such that (c) would
continue the reference value seen on the left and at the extreme right of
Figure 3.8. From the PCT modeler's point of view (a) is the disturbance d,
(b) is q.o, and (c) is q.i, which is not represented.
Control for words and syllables sets references for control of auditory
perceptions such as those represented here as values of F1, and
simultaneously sets references for control of what it feels like to produce
those auditory perceptions. The latter references are more immediately
affected by error in control of auditory perceptions, and that effect is one
object of these experiments. Conflict between that and control of what it
feels like to produce a given word or syllable (part of the input to word
and syllable recognition, along with other inputs such as e.g. spelling) is
another object of these experiments, phrased in terms of explaining why
subjects "fail to compensate completely". This 'puzzle' is what my talk at
Stanford addresses. Other inputs to the perceptual input functions for
recognizing and controlling words are discussed in my LCS IV chapter and in
a couple of related papers that I have posted in our Researchgate project.
/Bruce
--
Richard S. Marken
"Perfection is achieved not when you have nothing more to add, but when you
have nothing left to take away.�?
--Antoine de Saint-Exupery
--
Richard S. Marken
"Perfection is achieved not when you have nothing more to add, but when you
have nothing left to take away.�?
--Antoine de Saint-Exupery
--
Richard S. Marken
"Perfection is achieved not when you have nothing more to add, but when you
have nothing left to take away.�?
--Antoine de Saint-Exupery