[Martin Taylor 2009.01.24.10.46]
[From Bill Powers (2009.01.23.1034 MST)]
Martin Taylor 2009.01.22.17.40 --MMT requested:
We need one more column: model-target %ofmax.
I added that figure and did 5 runs:
` {FIT ERROR} { TRACKING
ERRORS}Diff delay gain damping ref model-real tar-model
tar-real60ths pixels % of max % of max % ofmax
1 3 14.2 0.000 -1.2 0.666% 0.344%
0.827%2 8 8.6 0.000 -2.0 1.287% 1.356%
1.920%3 8 6.2 0.004 -2.0 1.277% 2.581%
2.970%4 8 6.2 0.100 2.0 1.837% 3.136%
4.065%5 9 5.6 0.120 0.0 1.966% 3.316%
3.919%
`Note the monotonic rise in damping, again, as difficulty increases.
Gain also falls.
from the fit and tracking error percentages you
provided. I tried the triangulation test that I mentioned earlier. The
hypothesis in this case is that the model is a perfect fit to the
person’s control mechanisms and its parameters, except for “random”
noise in the person’s output (due to all sorts of possible effects
inside and outside the person).
The consequence of this variability would be to make the model-person
deviation (fit error) orthogonal to the model-target deviation. Why?
Because the underlying person-target track – the one the person’s
control system would do if not for the “extraneous” (of unknown causes)
variation – would be identical to the model track, and in a
high-dimensional system (the number of independent samples along the
track defines the dimensionality) any two independent sets of samples
are with high probability nearly uncorrelated. The correlation between
any two vectors is the cosine of the angle between them, so
uncorrelated vectors lie at right angles to each other, no matter what
the dimensionality of the space in which they are described…
What I did was to take the percentages to be distances in a space of
“fit”. The “space of fit” (my own term) for three vectors is a plane
defined by the ends of the vectors of samples in the high-dimensional
sample space. Then I used the distanced defined by the percentages to
draw triangles that represent the locations of the
target, model, and real tracks, in the planar “space of fit”, and look
at the angle Target-Model-Real. The angles, in order of tracking
difficulty, were 105.4, 93.1, 94.6, 106.7, and 92.2. They are all
fairly close to 90 degrees, but all are greater than 90 degrees. Here’s
what the triangles look like. The numbers represent the “difficulty”
index. The “Model-Target” base is scaled to be the same for each
example.

What do these triangles tell us? The most obvious is that for the
easiest and second easiest examples (labelled 1 and 2 in the figure)
the model is a rather better tracker than is the human, and is somewhat
better for the more difficult examples. But is this because the model
is wrong or because the human’s performance is noisy? Either is
possible. The model parameters are the best fit to the human data, not
to the target. In fact, the target is completely ignored in setting
those parameters. So why should the model track the target better than
the human whose data are used in the fitting? One might naively expect
the model to be better and worse about equally often.
A second obvious thing is that Difficulty 1 is much farther from both
Model and target than is Difficulty 2, which in turn is somewhat
farther than are 3, 4, and 5, which are much alike. Remember, these are
scaled results, but if the difference between the Model and the human
is due to noise variation in the human, it seems that proportionately
the noise is greater for the easy task and fairly consistent for the
three more difficult ones. I won’t pursue this here, but will consider
the implications of the angle Target-Model-Real. That will take quite
long enough ![]()
Going back to what I said above, let’s start a bit of Bayesian analysis
to see whether we can specify some hypotheses to compare. for these
data. We don’t have tracks to work with, so “D” in the hypothesis tests
are the fit error and the tracking errors (these are fits to the target
track, so we might as well call them all “fit errors”). Initially, at
least, I will use just one function of the three fit errors, the angle
T-M-R (the bottom left in the triangles). That’s a simple scalar value,
which makes things relatively easy. I will call it “d”, a diminished
version of D.
For the Bayesian analysis, we need at least one hypothesis, and
preferably more. In this case, I will use just one hypothesis H, and
develop something that functions like a confidence interval for d in
P(d|H). The hypothesis I will work with is “The Model accurately
represents the human control mechanism, apart from some random
variability in either the human or the mechanical control device”. This
hypothesis implies that the angle T-M-R is 90 degrees, but does not
specify the distribution of angle TMR to be expected in runs of 1
minute. For that, we must provide some conditionals, which are
assumptions that we assert for the purpose of the analysis.
For our purposes here, I think it seems reasonable to use a conditional
that the correlations among the samples are the commonly assumed linear
Gaussian ellipses, which implies that we just need to know how many
independent samples there are in the 1 minute run, because that will
tell us how much variation to expect if the true correlation is zero.
Whn the correlation is near zero, the variance of the correlation is
close to 1/N, where N is the number of samples. To get the number of
independent samples, we compute the autocorrelation function of the
error sample sequence (I used Excel). Not having the track data for the
runs in question, I used the data Bill P provided for an earlier run,
but since the same person did all the runs, and the result is used only
to estimate the variance of the angle TMR, I think this is probably
justifiable. The result looks like this:
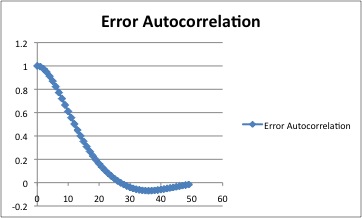
The correlation falls to zero near 25 samples, and there are 3600
samples in the entire run. This means that there are about 144
independent samples over the whole run. Now, working with our fallback
conditional of linearity and Gaussian distributions, the expected
distribution of the correlations in the data is nearly normal, with a
standard deviation of 1/sqrt(N), where N is the number of samples.
Remembering that correlation is the cosine of the angle between
vectors, that translates approximately into a standard deviation in the
angle TMR of about 5 degrees, from which we can compute P(d|H) for each
of the angles found above.
Since the possible values of d are continuous (in principle, the angle
could take on any value from zero to 180 degrees), P(d|H) is a
probability density rather than a probability, and it is probably more
useful to compute the equivalent of a confidence interval, using the
actual angles as limits. We ask “Given the hypothesis H (that the Model
accurately represents the human control mechanism, apart from
some random variability in either the human or the mechanical control
device) and the conditionals mentioned above, how probable is it that d
would as deviant from 90 degrees as the value we found?” In other
words, we integrate P(possible values of d|H) over the tails of the
normal distribution beyond the deviations we found, which were 15.4,
3.1, 4.6, 16.7 and 2.2 degrees.
Reading by eye off a graph of the cumulative normal distribution, I get
the following values of P(d more deviant than found, given H):
Difficulty 1 ~0.006
Difficulty 2 ~0.55
Difficulty 3 ~0.32
Difficulty 4 ~0.005
Difficulty 5 ~0.65
Note that these probabilities are not significance levels. There is no
“null hypothesis” unless “H” can be considered to be one. They refer to
the data actually obtained, but do use the probabilities that more
deviant data that were not obtained could have been obtained. These
probabilities are derived from H. They are not very precise, but should
be in the ballpark.
Looking at these probabilities, I personally would be quite happy to
accept H in the cases of difficulty 2, 3, and 5, but would be tempted
to look further in cases 1 and 4, were it not for one other pair of
observations. That pair consists of (1) that all the angles TMR are
greater than 90 degrees, and (2) that the autocorrelation function goes
negative for lags greater than 25 samples. The latter suggests the
possibility that the person may have a slight tendency toward
oscillation near 1.6 Hz, and the former that the person may perhaps
tend to deviate from the target more than the Model does, even allowing
for the effect of random variation. Both suggest the possibility that
there might be a possibility of slightly improving the structural match
between model and person.
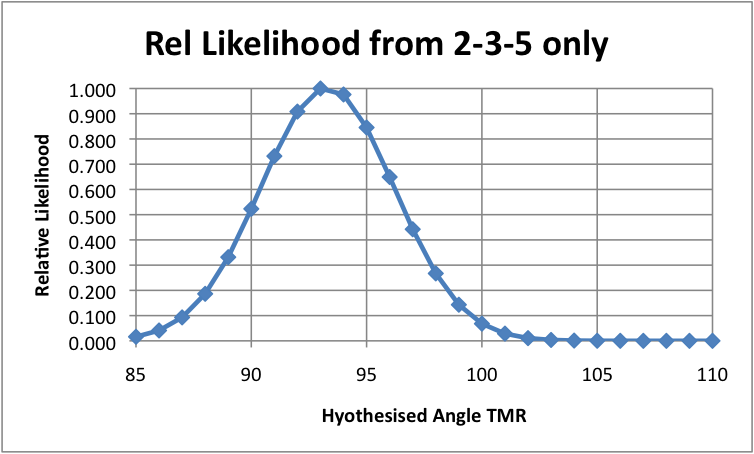
Can we justify any of this speculation with the data at hand? Let’s try
a Bayesian analysis that compares two hypotheses for each Difficulty
level. H1 is just the same H that we used previously, whereas H2 is a
hypothesis that the underlying angle TMR is 95 degrees rather than 90
degrees, for all of the difficulty levels. We have no
control-theoretical justification for H2, but it is interesting to see
whether this notion might be worth pursuing further.
For this test, we can use the probability density values rather than
their integrals. This is philosophically cleaner, because there is no
reliance on imagined possible data. We use only the data observed. The
probability density values are read off the normal Gaussian curve.
These curves are usually drawn so that their integral is 1.0, which
puts the peak at about 0.4. The P values are relative, so scaling does
not matter. They are not probabilities, but relative probability
densities.
The angular deviations from H1 and H2 are:
`Difficulty H1 H2 P(d|H1) P(d|H2) P(d|H2)/P(d|H1)
1 15.4 10.4 0.002 0.05 25
2 3.1 1.9 0.3 0.35 1.2
3 4.6 0.4 0.27 0.4 1.5
4 16.7 11.7 0.002 0.04 20
5 2.2 2.8 0.36 0.34 0.94
Combined P(H2|D)/P(H1/D)~= 850/1
`If these were the only possibilities (angle TMR = 90 degrees or 95
degrees, the same for every case), the data would point pretty strongly
to a preference for 95 degrees. In practice, two things argue against
so restricting the possibilities to be considered. One is that 95
degrees was chosen completely arbitrarily, and the other is that one
might introduce a new hypothesis H3 that said there is something
different about runs 1 and 4. The first can be handled by allowing the
hypothesised angle TMR for all the cases to be an arbitrary value,
meaning that we test a continuum of hypotheses of the form “Angle TMR
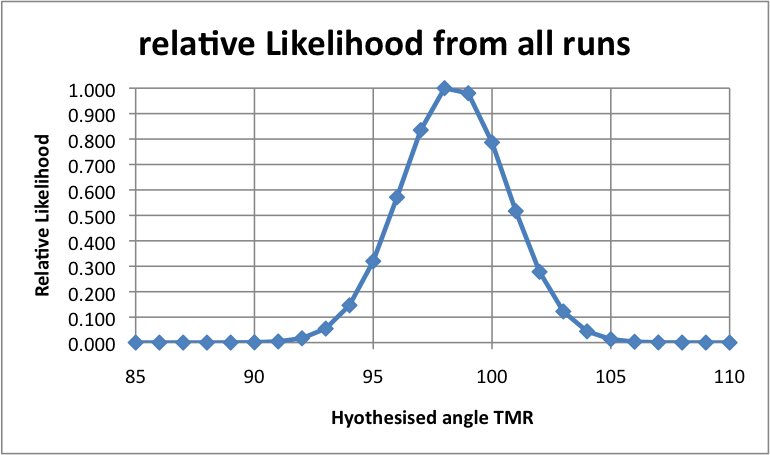
is x degrees” for any x in an interesting range, say 85 to 100 degrees.
The result would be a curve of values of P(d|Hx) normalized to some
specific value of x, such as 90 degrees, or normalized so as to make
the maximum 1.0. The second could be handled similarly, but instead of
doing this, one would probably prefer to get other data to look for
possible differences among the five cases.
This has been pretty long-winded, but I wanted to suggest how even
quite sparse data can at least suggest plausible inferences about
control systems. In this case, the data suggest that the Model is
plausibly accurate apart from human variability, but even so, there may
well be a consistent deviation of human from model performance, perhaps
related to a slight tendency toward a human oscillation, perhaps to
some other characteristic that makes the best-fit model track the
target a little better than the human does, even allowing for human
noise variability.
Because in another message I said I would post this before going to
bed, I’m going to go against my better judgment, and do so even though
the time is about 1:20 am. I hope I don’t wake up knowing that I’ve
made a glaring error, as I did when I posted my message amout Rick’s
demo at a similar time of night.
Martin