[From Erling Jorgensen (2018.11.30 1410 EDT)]Â
EJ: In the System (person) equation, it looks like there should be two more closed-parentheses marks. I am forgetting how much of what follows ‘slow’ is multiplied by, and how much is ‘gain’ multiplied by. It seems there should be an extra parenthesis mark after ‘pOtherCI(t))’ and an extra one after ‘Output (t-tau)’. If so it would read:
Output (t) = Output(t-tau) + slow * (gain* (r - (pSelfCI(t) - pOtherCI(t)))-Output (t-tau)) (1)
EJ: Is that right? Or does the slowing factor just multiply the product that the gain factor just produced?Â
RM: No you’re right. The slowing factor is a proportion of the change in output produced by the multiplication of gain times error. I got it right in the computer code:Â
Output(i) = Output(i) + 0.5 * (0.8 * -(pSelfCI - pOtherCI) - Output(i))Â
where i is the index of the individual in the population for which the output is being calculated. The slowing and gain factors that are shown (.5 and .8) are the one’s that seemed to work best in the sense that they led to a stable outcome after a few trials. But other values in the range of those work pretty well also.Â
EJ: Along this line, what slowing factor are you using and what gain are you using in the current version of the model? Â
 RM: See above.Â
EJ:Â Just a word about how reference values are being affected here…
EJ: Typically, perceptions get adjusted to match reference levels. But how are reference levels established
 RM: In the model the reference is set by me. An extension of the model would be to add a level of control, such as a level that controls for imitating only high prestige members of the group, and have that level set the reference for the difference between self and other pronunciation to 0 if the other is prestigious and perhaps to some small number if the other person is not prestigious. Setting the reference to be not equal to 0 will cause the system to control for making the self CI differ from the other CI by a small amount.
EJ: The center of equation (1) has abbreviated terms of [… r - (pSelf - pOther) …], which becomes [… r - pSelf + pOther …] In other words, the observed pronunciation of the Other gets added to the reference, ‘before’ one’s own pronunciation is subtracted. And with each person’s reference initialized to 0, that means the other person’s pronunciation becomes the de facto reference value for each person’s drifting perceptual control.Â
 RM: That is a brilliant observation. I could have written my computer equation as follows:Â
Output(i) = Output(i) + 0.5 * (0.8 * (pOtherCI - pSelfCI) - Output(i))Â Â Â
RM: And it would behave exactly the same! And it could be interpreted as the other person’s pronunciation, pOtherCI, being the reference specification for one’s own pronunciation, pSelfCI. And this is precisely the way non-PCT applications of control theory to behavior have modeled behavior; the error that drives “behavior” (output) was seen as being in the environment, where the causes of behavior are though to be by conventional psychologists. And this way of applying control theory (which involves all kinds of impressive math, such as some members of this group find to be evidence of understanding a theory) “works” in the sense that it accounts for data in situations where the controller is not varying their reference for the perception being controlled.Â
RM: What Powers did was point out that reference specifications perceptual states of affairs are inside the controller, not out in the world. Nothing outside of the individuals on Martha’s Vineyard who were controlling for matching their pronunciation to that of another person told them to keep the difference between pOtherCl and pSelfCI equal to 0. The difference between pOtherCl and pSelfCI – pSelfCI - pOtherCl – is a perception that is being kept equal to a reference of 0 that is inside the person. It’s easy to demonstrate that this is the case by simply changing from controlling for imitating the way another person pronounces something to controlling for pronouncing it as differently as possible. Â
RM: So rather than writing the error calculation in my model as (pOtherCI-pSelfCI)Â I write it as r- (pSelfCI -Â pOtherCI) to make it clear that error is r-p and that the controlled p is the difference between self and other pronunciation in terms of CI, pSelfCI- pOtherCI.Â
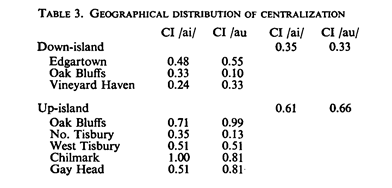
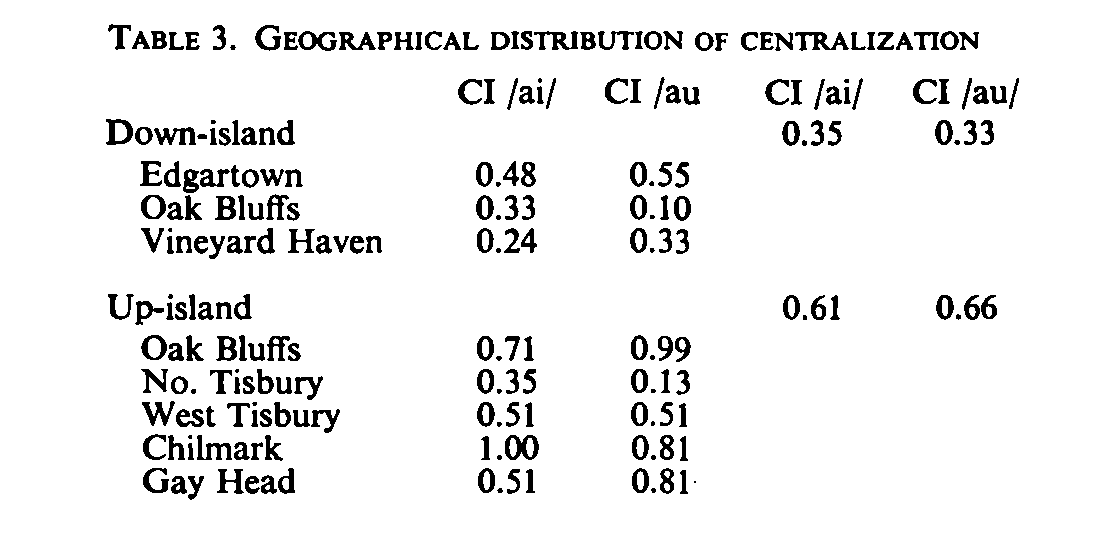
EJ: I assume that the initial values of (pSelfCI) are assigned randomly, seemingly with Centralization Index values varying between .00 and 2.00. Is that correct?Â
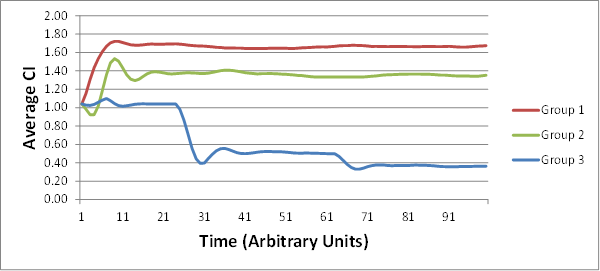
RM: Yes, exactly! Though, in order to start all three groups with the same average CI, I use the same 10 randomly selected CI values as the starting CI values for each group.Â
EJ: With the only constraint being that each Group starts with the same AverageCI among its 10Â members as the other two Groups.Â
RM: Yes, see above. Â
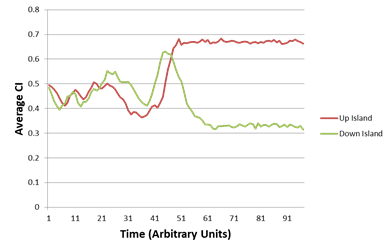
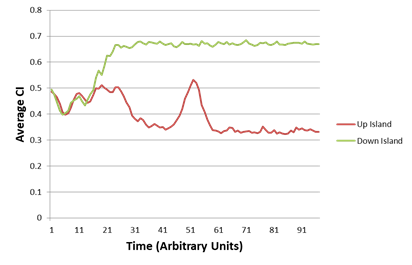
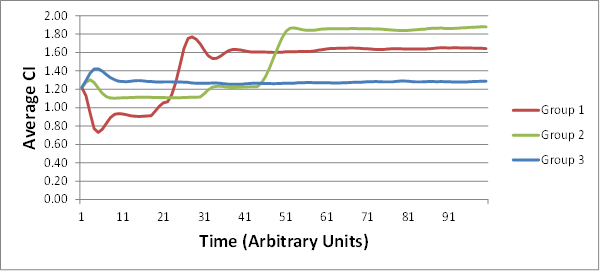
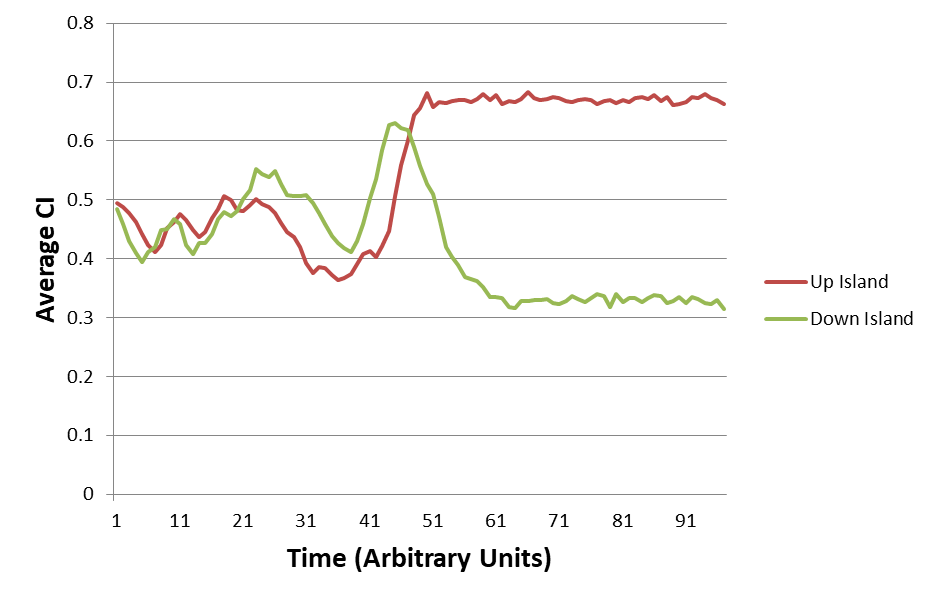
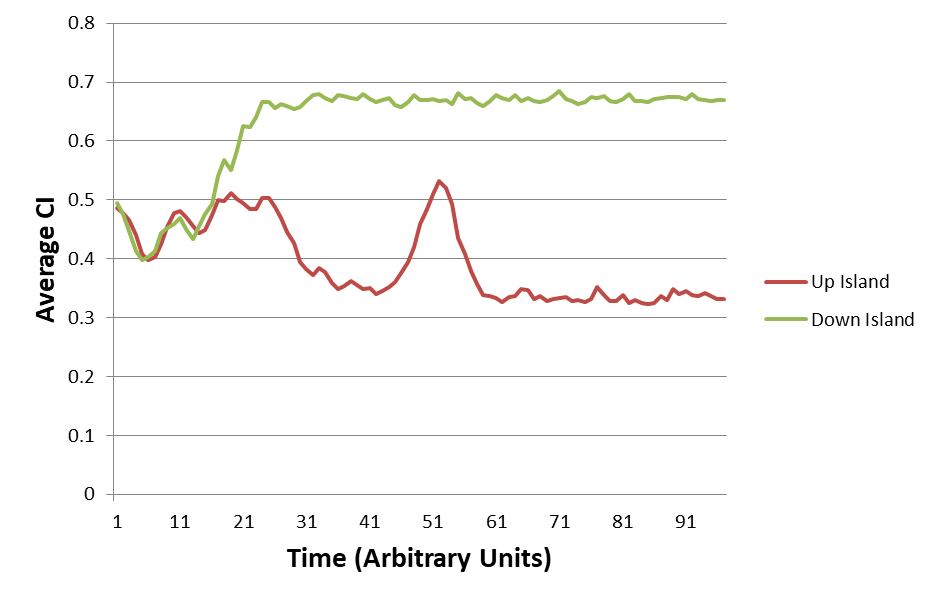
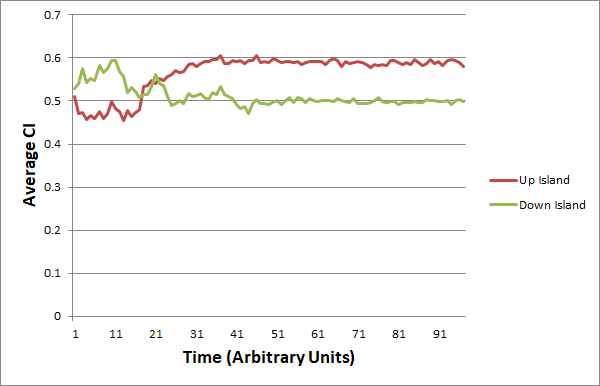
EJ:Â That’s the part that’s so striking about the representative graphs that you provide in –
EJ:Â I am stunned that each group’s AverageCI migrates to a new fairly stable value that is different from the other groups!Â
RM: Yes, I agree. It was pretty exciting to see it work that way!Â
Â
EJ: And all of that as a side effect of iterative interactions between fluctuating dyads within each (geographic) group.
RM: Yes, indeed. Â
EJ:Â I know you graph the changes over time as "arbitrary units."Â But can you give us some idea of the number of iterations?Â
RM: Actually, the numbers are the iterations of the program. Â
EJ: Is it really the case that it only takes from 10 to 20 rounds of random interactions (among 10 members of a given group) for some of the groups to converge onto a stable AverageCI? That’s pretty amazing.Â
RM: Yes, it usually takes from 10 to 20 iterations to reach stability, though you can make it take more iterations by using a smaller slowing factor. But reduce the slowing too much and the individuals don’t control very well and the average CI doesn’t ever reach stability. The observed average stability occurs only when the individuals have good control of their perception, pSelfCI- pOtherCI.Â
RM: But these results look so good that I do want to be sure that there is no mistake in the coding that produces them. So I will keep checking it out as I go. But I am also attaching the spreadsheet that runs the model so you can run it and see what happens. If you know Visual Basic you can open up the program in the “Run” button and possibly get some idea of how it works, though I’m not particularly good at documenting my programs. Since the spreadsheet contains a program macro it will give you a warning when you open it but don’t worry, there are no viruses in it. I just hope the email let’s it through. IF it doesn’t you can get it from DropBox:
https://www.dropbox.com/s/54tlwgmjin2pl0v/CI%20Control%20Basic%20Model.xlsm?dl=0
Â
EJ:Â I really appreciate you and Bruce N. doing this joint hypothesizing and model building ‘out loud,’ so to speak, so the rest of us can listen in and see how a proposed PCT model might be applied to a given set of data.Â
RM: Thanks. And I agree, this could be a great way to learn how to do PCT research using archival data and computer modeling. And the computer modeling itself is a great way to learn PCT. Â
Â
EJ: It is impressive that stable group data can emerge as side effects of individual control system interactions.Â
RM: Ain’t it though!! I thought it might work but I had no idea that it would work so well. But there is still the problem of figuring out whether we can get average CI to a particular destination based on age and social aspects of the “others” with whom each person is speaking.
EJ: (Which, by the way, is exactly one of the take-away lessons of the CROWD simulations.) I especially like how the model is built up, one approximation at a time, to see how much of the phenomena can be handled by a relatively simple model, before adding further refinements. Nice job, Rick.Â
RM: I agree about the lessons of CROWD and building the model one step at a time. I’m really glad you like it! This is what I always hoped the CSGNet would be used for – collaboration rather than confrontation.
Best regards
Rick
CI Control Basic Model.xlsm (101 KB)
···
–
Richard S. MarkenÂ
"Perfection is achieved not when you have nothing more to add, but when you
have nothing left to take away.�
                --Antoine de Saint-Exupery



 . As I see the situation it seems that you are getting to where Bruce Nevin wants you to go. You’ll probably get the conclussion that in avarage people in vicinity pronunce in the same way. So the conclussion will probably be that Bruce Nevins’ theory is right. The transmission in pronauciation is done with “perception of reference values”. You know what Bill thought about “statistical analysis”. And in PCT we know that “reference values” can’t be perceived.
. As I see the situation it seems that you are getting to where Bruce Nevin wants you to go. You’ll probably get the conclussion that in avarage people in vicinity pronunce in the same way. So the conclussion will probably be that Bruce Nevins’ theory is right. The transmission in pronauciation is done with “perception of reference values”. You know what Bill thought about “statistical analysis”. And in PCT we know that “reference values” can’t be perceived. .
.