I don’t know where this idea that collective control requires the individual controllers to directly influence one another came from. Even in Kent’s one-dimensional demo of collective control by conflict, the individual controllers affect each other only through their effects on the observable environmental variable that is collectively controlled. By the nature of a control loop, that it perceives only the variable is is controlling, neither can perceive anything at all about the other.
I’m not sure what you mean by the “more complex case” but I think you might be referring to Labov’s data on differences in pronunciation associated with different social variables, such as occupation and age. My model, which accounts for the emergence of differences in pronunciation associated with a geographical variable, is a description of a mechanism – control for imitation – and it can surely account for differences in pronunciation associated with the social variables as well.
My model is, indeed, a model of imitation because it involves comparison of a perception of the output to be imitated to the system’s own output and acting, by changing the reference for the pronunciation, to be more like the output that is perceived.
They effect each other, not directly, but via their effects on the commonly controlled variable.
I can’t see what message you are referring to or who authored it. If you are referring to something I wrote, I would not have been referring to anything to do with pronunciation.
If you are referring to something I wrote, I probably was considering the usual situation in collective control, where no two members of the collective control exactly the same perceptual (and therefore environmental) property variable in Perceptual Reality.
No, I won’t simulate it because I already have. And it has nothing to do with the fact that, in Kent’s model many (and possibly all but never none) of the individuals who are keeping a variable in a virtual reference state are experiencing error, sometimes massive error.
This one from Bruce.
Could you provide a link to show the results you got when you simulated the case in which person A controls a perception of say x+y while person B controls 0.9x+1.1y?
Martin, in Rick’s post where you saw this, in order to see the context in my prior post, click my name bnhpct at the top of his post, and it expands above. I mean this post (his link was off by one — for the right index number to appear in the URL you have to scroll so that the text bridges the upper boundary of your browser window, not hard for a long post but tricky for a short post).
Yes, that’s a good example for starters, still relatively quite simple.
How do you model how these social variables are perceived and controlled? How do the autonomous agents in your model perceive these attributes in one another and how do they control how these attributes appear to one another — in your model? What are the perceptual input functions and what are the effectors that you are modeling and how do you model them?
The ‘centralization index’ in Labov’s Martha’s Vineyard data is an abstraction from more complex perceptual data, a convenience for analyzing the issue and presenting results. There is no empirical or experimental basis for asserting that it is perceived and controlled as such. Could be, but nobody does anything with it, maybe some speech pathologists, and again as an abstraction for convenience.
I did it long ago and don’t have the simulation. So I cobbled together a new spreadsheet that shows that this is true. The spreadsheet is here. The spreadsheet shows that your predicton holds for the two coefficients you mention (.9 and1.1) and, more generally, for all possible coefficients of x and y for person B in the conflict. That is, the spreadsheet shows that the the virtual variable that is always controlled when A controls the variable x + y and B controls the variable k1x+k2y is ((1+k1)/2)*x + ((1+k2)/2)*y. It also shows that this is true regardless of the reference values for x and y.
Here is a display of the results that you will see when you open the spreadsheet:
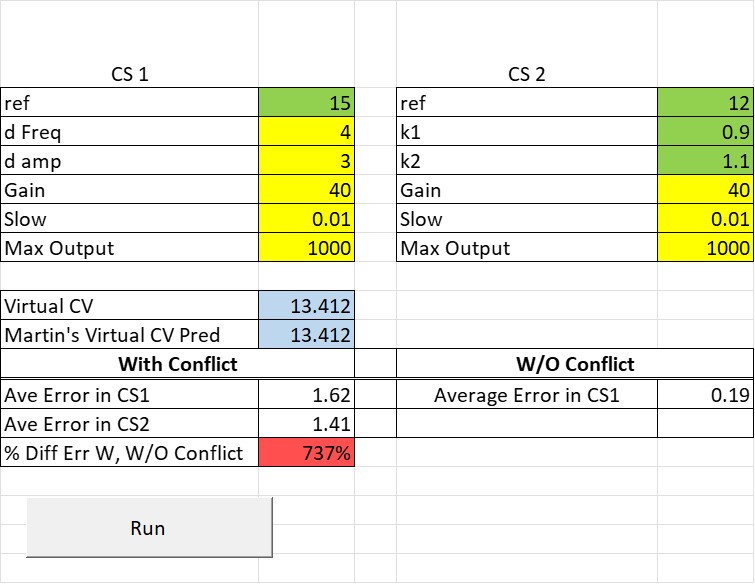
There are two control systems: CS1, which is controlling x+y, and CS2, which is controlling k1x + k2y. The values for k1 and k2 can be set by entering values into the green cells to the right of k1 and k2. They are currently set to the values you suggested, .9 and 1.1. But any two values will work.
The value in the cells colored yellow are parameters of the control systems. They can be varied but I would leave them alone for now until you get used to using the spreadsheet. The current parameters define two control systems of equal ability (gain and slowing) with the same limit on the amount of output that they can generate.
The values in blue are the actual (computer) value of the virtual controlled variable (labeled “Virtual CV”) that emerges from the conflict and your predicted value of that variable (labeled “Martin’s Virtual CV Pred”) per the equation above: ((1+k1)/2)*x + ((1+k2)/2)*y. The values are always identical,confirming Martin’s predition. This shows that when two control systems control two differnet functions of the same environmental variables (x and y) the result is a virtual controlled variable whose value is midway between the values desired by each control system.
Although this spreadsheet shows that it is possible to make a very accurate prediction of the value of a virtual controlled variable that emerges from the interation between two control systems controlling different perceptions of the same environmental variables, can’t think of a real world example of phenomenon that corresponds to what the moel is doing. Well, maybe arm wrestling and tug of war.
Neverltheless, I think the spreadsheet was worth developing because it nicely demonstrates my point about the existence of significant error in the individuals that make up a collective (in this case, a collective of two indivisuals) keeping a virtual controlled variable in a reference state that differs from the reference states of the indiividuals in the collective. This can be seen by pressing the “Run” button, which automatically runs a conflict between CS1 and CS2 with those two control systems controlling x+y and k1*x+k2y, respectively, relative to different references, and then does a run with CS1 controlling x+y on its own.
The results are shown oin the table just above the “Run” button. The table shows the size of the error signal (in units of neural current) in CS1 (and CS2) when they are in conflict and when CS1 is controlling on its own. The percentage increase in the size of the error experienced by CS1 when in conflict versus when controlling alone is shown in the cell colored red. The table above shows that when the two conrol systems are in conflict , controlling relative to fairly different references (15 and 12) CS1 is experiencing over 700% greater error while maintaining the virtual controlled variable in its reference compared to when CS1 is controlling without the conflict.
In real life, error corresponds to pain in the form of stress and anxiety. The spreadsheet shows that the pain experienced when in a conflict can be a very high price to pay for keeping some variable in a stable virtual reference state.
Best, Rick
A better question is “why would I want to model them?”. There is nothing in the data that sugggests that these social variables are (or are not) controlled. From my own observations about social variables, I would say they are relevant to the topic of Labov’s paper (differences in pronunciation across differetn geographical and social groups) only insomuch as people who identify as being in particular social groups may tend to interact with each other more than with individuals outside their groups. Since there is no data (in the paper, anway) on the frequency of in versus out group interaction for the different social groups I don’t see what a model could do in terms of predicting differences in pronunciation across social groups. A control model, that is.
There is nothing in the data that suggets that people do perceive these attributes or, if they do, how they do it.
Again, there is nothing in the data that suggets that people control for how these social attributes appear to one another.
In my model the perceptual input functions are simple transducers that perceive the CI value produced by the speakers and the corresponding CI value spoken by the listeners, and the listeners adjust their CI value on each iteration of the model to be closer to that of the speakers.
All data is abstraction in that sense; cursor-target distance is an abstraction based on the relative positions of two lines. But what’s interesting about this CI data is that it’s average value differs across geographical and social groups.
The fact that people consistently produce CI indexes that are recognized as a particular diphthong provide a strong basis for assumimg that the CI index – or a closely related variable – is a controlled result of action. But even if what is controlled is a variable that is just related to the CI index, the fact that the CI index is consistently different across regions is a phenomenon worth trying to explain with a control theory model of the people producing this result. And my model is a start at providing that explanation.
Best, Rick
(I sent this some hours ago by email reply, but it did not ind its way here.)
Hi Rick,
two quick questions:
Does the Run button do something else than F9? My work laptop does not allot me to run macros (and it is the only one I have available).
Why CS2 has a slightly lower average error than CS1?
Eetu
Yes, the “Run” button zeros out the max output values (you can do it manually) which zeros the outputs of CS1 and CS2 and then it resets the max to 1000. This is done so that you get clearer results; there is some ugly oscillation that occurs when the outputs reach max, which is probably an artifact of the way I wrote the code in Excel. The “Run” macro does some other things as well to get you an accurate measure of the difference in error in CS1 when it is controlling the same variable with and without conflict. So it would be nice if you could get to a platform that would let you run excel with VB macros.
Because CS2 is controlling a different perception than CS1; CS2 is controlling .9x + 1.1y while CS1 is controlling x + y. If you change the values entered for both k1 and k2 to 1.0 you will find that CS1 and CS2 end up with exactly equal error. Other settings of k1 and k2 will result in CS2 having a higher error than CS1. Why this happens, I’m not completely sure but I think it has to do with the extent to which the outputs of CS1 “help out” CS2.
Hi Rick,
two quick questions:
Does the Run button do something else than F9? My work laptop does not allot me to run macros.
Why CS2 has a slightly lower average error than CS1?