Hello
I have been simulating the JOOSS sequence from chapter 11 in B:CP, programmed in Python.
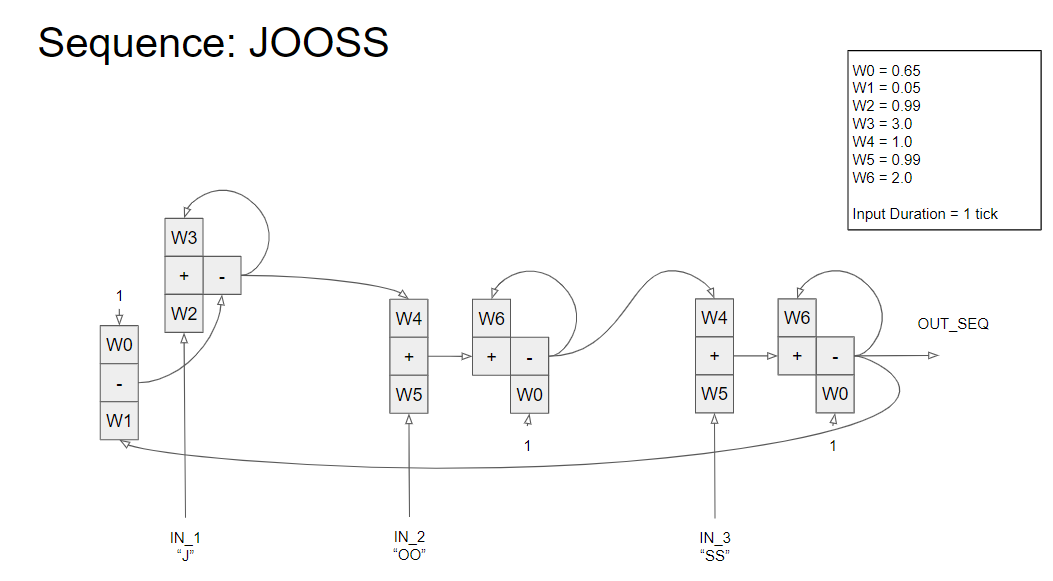
The goal is to not use programming language constructs but some element functional unit which can serve as basis for all PCT modelling (comparators, input/output functions, etc). See attached for the complete model.
I have attached an image of the model, with each of the 6 elements realized using the equation:
out(t) = s1*in1(t)w1 + s2in2(t)w2 + s3in3(t)*w3
where s is the sign (+ or -) and w is for a weight.
All signals are floats varying between 0.0 and 1.0.
Weights vary between 0.0 and 4.0.
So, the functional execution of the model is from left to right, sequentially, and the signals flowing from right to left is updated the next iteration.
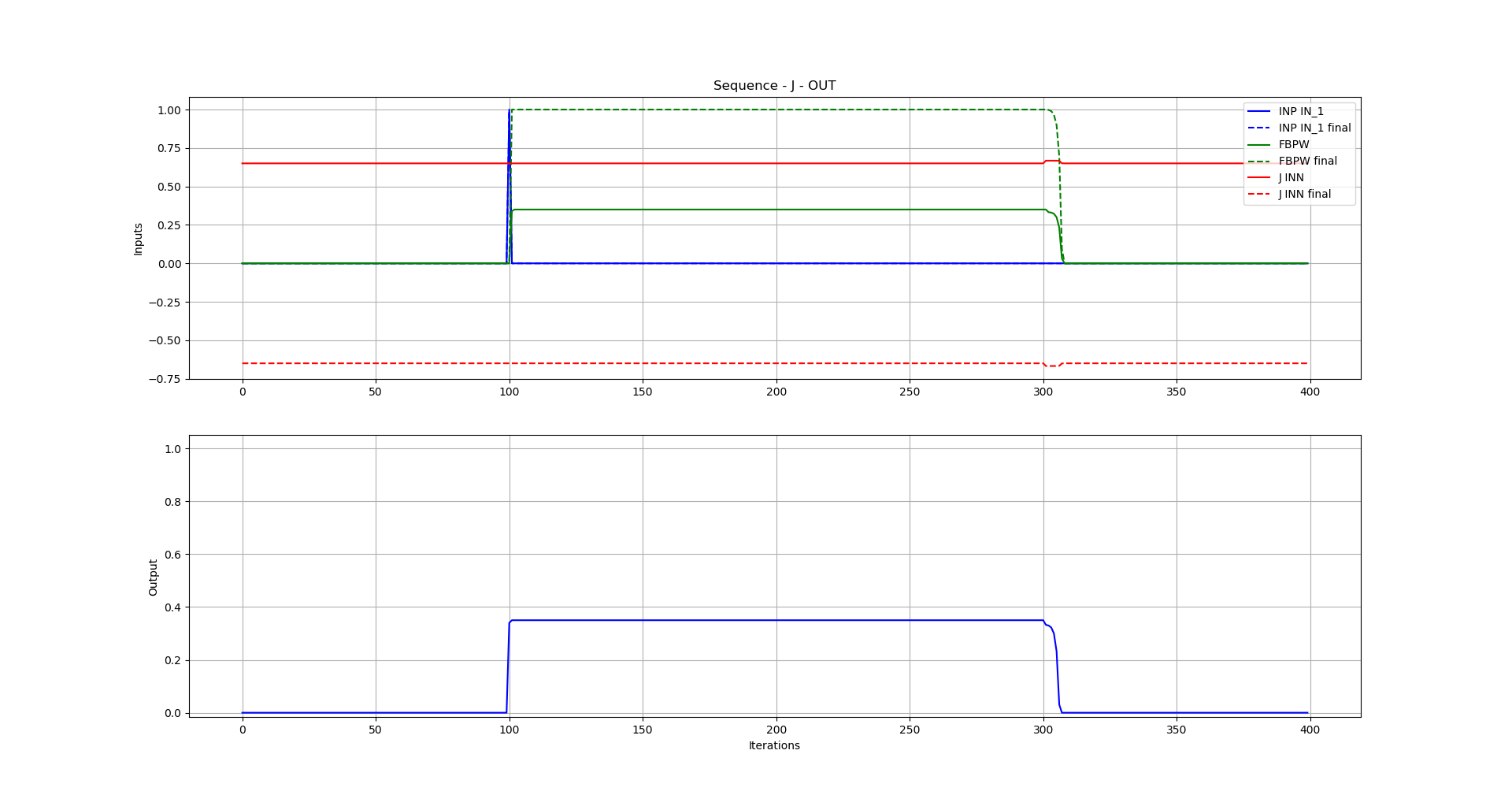
I have simulation plots as well, done with matplotlib (an example of the output of the second element is attached).
So, the model seems to work, following how it is described in the book.
My questions are:
(1) Has anyone else done a simulation of that sequence using functional elements (not lines of code) as building blocks? If so, which functional element worked for you? How did you simulate “time”?
(2) If able to implement the JOOSS sequence, has anyone actually tried to input a recording of someone saying the word “juice” and have if fed to this model and have the sequence be detected? I am aware this will not be simple, given that many sublayers in the hierarchy need to be added.
Paul