I’m glad to hear that you agree
that there may be some valid
applications of statistics. Is it just the use of regression for
individual prediction that gets you so upset about
statistics?
If so, could you tell me what
you would do if there were a limited number of
slots available for students in college (as there are, due to
funding
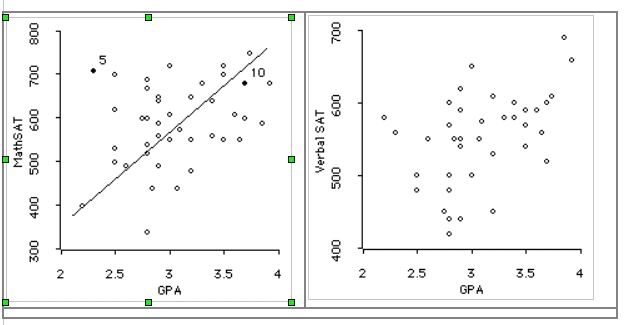
limitations) and you wanted to put the most promising students in
those slots; how would you select the students for the
slots?
This is the situation
administrators are in when they are accepting students
into colleges. Should these administrators ignore the statistical
data, that shows that kids with high SAT scores tend to do better in
college, and just let kids in on a first come first basis or
something
like that?
I especially agree with
your recommendation that any proposed health
insurance plan be tested to see if it will actually be an improvement.
If
everybody could agree to that, nobody would have to take a position on
what
the best plan would be. We would simply find out.
What kind of test would you accept?
The best test would be a
completely randomized design which would involve dividing the US
into
two randomly selected groups of 150,000,000 each (that way we could
avoid sampling and the use of the dreaded statistics). One group
(treatment group) gets a single payer and the other (control
group)
stays with the existing system. You would then have to measure the
performance of the two groups (infant mortality, life span, etc)
over
some acceptable period of time, like, maybe, 20 years. Then you
compare the groups in terms of the measures you consider relevant.
You
wouldn;t have to use statistics because you are testing the entire
population; no inferences necessary.
I see a few possible
problems with this approach to testing policy
proposals: The study would cost a bazillion dollars, it would take a
long time, and when it was completed it is likely that those with
vested financial interests would challenge the results anyway, to
the
extent that they came out in the “wrong” way.
The fact is that the only
practical way to test policies is using
“quasi-experiments”, the specialty of Donald T. Campbell who
was one
of the few prominent conventional psychologists to admire you work.
A
quasi-experiment is one where there is no true control group. For
example, a quasi experiment is done when different health care
systems
are implemented in different states or countries. These groups are,
of
course, not exactly equivalent before the treatment but you do the
best you can to decide the extent to which any observed difference
in
the performance of the groups is a result of any of the initial
differences between the groups or a result of the treatment. One way
to do this is to factor out (statistically – yikes) potential
confounds that are thought to be important, such as income levels or
health levels of all participants. This is called analysis of
covariance. Another way to do this is to look at time changes in the
performance variables – so called “time series”
designs.
I have done some time series
“quasi-experiments” with economic data
(which you seemed to like at the time).
One nice example was
looking
at the US budget balance from 1980 to 2004. The question was whether
the policies of the Clinton administration (the treatment) were
responsible for the budget surplus that existed at the time Bush II
entered the White House. The data show that the budget hovered in a
deficit during the years before Clinton came in. Then the deficit
steadily and nearly linearly moves into surplus through the Clinton
years and then instantly turns back toward deficit when Bush comes
in.
I measured growth over the whole
period and showed that this potential confound varied in the same way
before, during and after Clinton. So it was not a
confound.
There may be time series data
that could be used to test health care
policy questions, but it’s unlikely that there is reversal data
(unless there is a country that went to single payer and then went
back). But there is all kinds of quasi-experimental data that is
available for testing health policy. The vested interests and
ideologues are going to reject that data anyway-- like the data on
the
cost/effectiveness of Medicare, the VA, the French system, etc –
but
this kind of data (which you spurn as “statistical”) is a lot
cheaper
than the completely randomized design (sans sampling so that it is
not
statistical) that I mentioned initially as the correct way to test
the
effectiveness of health care policies. And, though not perfect, it
seems like a reasonable basis for making informed policy
decisions.
I do take issue with one comment
in Kenny’s otherwise nice discussion
of statistics. Kenny said:
I often see uses of statistical
data in studies and experiments
where conclusions are drawn and future results are claimed that
are not justified by the analyses. Among the worst are using
correlation as evidence of cause.
The idea that “correlation does not imply causality” is a
methodological, not a statistical concept. Correlation is an
ambiguous
term; it refers to a descriptive statistic (r, the correlation
coefficient) and to the way data is obtained. r is just a measure of
the degree and direction of linear relationship between two
variables.
It doesn’t imply that there is nor does it imply that there is not a
causal relationship between the variables.
If, however, the data were
collected using experimental methods – where all variables other than
the independent and dependent variables are controlled (held constant) –
then a correlation (r) between the IV and DV does imply causality; the
correlation (r) means (according to standard research methods
assumptions) that variations in the IV do cause variations in the
DV.
I imagine Kenny must have meant
that it
is a mistake to use statistical measures based on group data (like
the
least squares regression line) as a predictor of individual results.
And if this is a mistake (which I don’t think it is) then you’ve got
a
heck of ‘splainin’ to do to a lot of college admissions officers,
who
use grades as a basis for predicting school performance, and
business
executives, who use data on past performance as a basis for
hiring.
[From Bill Powers (2007.07.20.1715 MDT)]
Rick Marken (2007.07.20.1430) –
.
I have always agreed, and have said many times, that there are valid uses
for group statistics. I don’t know where you get off implying otherwise.
The only invalid use is the attempt to use them to establish facts about
individuals. If you study groups, the facts you get are about groups. If
you study individuals, the facts you get are about individuals. You have
to show that some statement is true of essentially every member of a
group before you can use it successfully to predict what any individual
in the group will do. That means your group statistics must involve VERY
high correlations. That is almost never the case.
In the first place, the most promising individuals will get educated
anyway; I would give preference to those who need help more. Picking only
the best students who will learn even from a lousy teacher makes the
school and teachers look good, but doesn’t help the students who need
education the most.
In the second place, if the goal is to make the teaching look good, then
group statistics is the way to go: it doesn’t matter which students
benefit, as long as more people with the desired characteristics are
obtained through the screening process than without it. The ones who are
rejected are not your concern. If you pick people from group A (students
with high SAT scores), group B (the graduates from the university) will
do better than graduates who had low SAT scores would do. It doesn’t
matter which individuals are more successful – that is why you can use
group statistics. And it doesn’t matter if quite a few do worse than
expected, as long as the average goes the right way.
I would prefer individual interviews by the people who are going to teach
the students, with desire and ability to learn being weighted more than
past performance. Of course that is not practical when there are 5000
students from all over the country to be interviewed in the space of a
week or two by 10 or 20 faculty members. Anyway, it’s cheaper and easier
just to administer a test and hire a clerk to sort the results by score.
That’s why it’s done that way, not because that way is better for the
students.
I have the same question about this way of screening candidates that I
have about every other use of group statistics to deal with individuals.
How many students who will do poorly are accepted, and how many who would
do very well are rejected, by this method? A person who doesn’t care
about any of the individual applicants can safely ignore this question,
and use group statistics, and be sure of showing a good record of
successes, because success is measured as a group average. But if my
question is considered important, one simply has to do the arithmetic and
find out what the answer is. I’m sure the data are there. It’s just that
interest in finding this particular piece of information is very low,
possibly because everyone knows pretty much what the result would be,
though it’s not discussed in polite company.
If a student has any choice, my advice would be not to take any of those
tests, because the chance of being wrongly classified is very high (or so
I claim, until someone shows me otherwise). Unfortunately, if you don’t
take the tests you don’t get in, so you have to take them.
Very simple. Try out the system locally, and ask everyone how it’s
working and what the problems are. Study all the individual cases, and
THEN aggregate the results. Most systems that are put in place don’t even
do that much: whoever yells the loudest or buys the most votes gets his
system put in place with little or no pretesting. Then they defend it
against all criticisms.
We could eventually get that kind of data, but why not try it out on a
much smaller scale first? If a very clear advantage can’t be seen in a
small study, there’s no point in doing a larger one to see if it still
holds up. Large studies are large usually because on a smaller scale no
clear effect can be shown to exist, so (I would say) the approach is not
worth pursuing – unless you’re only interested in slight group average
effects.
Yes, that is why these full-scale expensive and grandiose proposals are
sure to be turned down. If I were against finding out the truth about
health care or education, that is exactly the proposal I would make to a
congressional committee. Then nobody could blame me when the proposal is
turned down.
This is fine if all you want to know is facts about groups. If you want
to apply the results to individuals, and care whether you treat each
person appropriately, you will not do it this way.
I did. It was valid group data about group phenomena. The conclusions
were not used to determine the fate of any individual in
particular.
No problem. Policy effects are group effects. If you examined individual
cases you would find many, many deviations, both small and large, from
the average relationships. The facts you cite are group facts, not facts
about individuals.
You were judging the effect of a policy on average effects over the whole
economy. A perfectly valid use of group statistics.
I wish you would stop trying to set me up as an enemy of statistics just
because I object to one egregious misuse of it. I may be dumb but
I’m not that dumb. I’m an enemy of the thoughtless, automatic,
superstitious use of group statistics as a way of finding out something
about an individual. I consider that to be a kind of formalized
prejudice. The point I have been making (and Richard Kennaway produced a
very detailed demonstration that I was more right than I knew) is that
you can use group statistics this way only if the correlations are in the
high 90’s – that is, they are seen in almost every case. If they are in
the 80s or lower, the number of misclassifications is entirely
unacceptable (to me).
Kenny’s point as I see it is that you should never use correlation alone
as evidence of causality, even though people do that all the time. If you
want to show causality, you have to use a different kind of evidence,
which is harder to get since it involves testing specimens instead of
casting nets. With group statistics, you can’t even show that a
particular B is caused by a particular A or set of As-- and what other
kind of causation is there?
Anyway, isn’t a a contradiction in terms to say that A causes B –
sometimes? Doesn’t that mean that A causes B except when it
doesn’t?
True, but you’re using a different kind of data than is required just to
calculate a correlation. You’re looking at individual cases. You’re
analyzing causality for individuals, then deducing the effect in
groups.
On the contrary, they have a lot of explaining to do about why they
insist on using mass measures to screen individuals on the basis of
correlations that are far too low to allow doing this one person at a
time. The only explanation they could possibly offer is that they don’t
care about individual cases – only about overall averages.
I think your spreadsheet is a sufficient example of a case where using
the linear regression line yields ludicrous predictions (negative infant
mortality rates), and entails large quantitative prediction errors (100%
or more) in over a quarter of the individual cases, not to mention
generating mis-rankings by 20+ places (United States predicted third from
best, actually 25th from best).
I’m willing to pipe down if someone can show me that predicting
individual behavior from group statistics, at correlation levels commonly
accepted as good, does not seriously misrepresent large numbers of
individuals. Or else convince me that misrepresentation doesn’t matter.
Your spreadsheets so far have worked in the oppposite direction.
Best,
Bill P.