- Galantucci, Fowler, & Turvey (2006), The motor theory of speech perception reviewed, Psychonomic Bulletin & Review 13(3):361-77.
- Whalen (2019), The Motor Theory of Speech Perception, in Oxford Research Encyclopedias: Linguistics (online).
- Laurent, Barnaud, Schwartz, Bessière, Diard (2017), The complementary roles of auditory and motor information evaluated in a Bayesian perceptuo-motor model of speech perception. Psychological Review, American Psychological Association, 124.5:572-602.
- Iljina, Derix, Kaur, Schulze-Bonhage, Auer1, Aertsen, & Ball (2018), Real-life speech production and perception have a shared premotor-cortical substrate.,
“Our fndings show that an electrostimulation-defned mouth motor region located in the superior ventral premotor cortex is consistently activated during both [production and perception] conditions. This region became active early relative to the onset of speech production and was recruited during speech perception regardless of acoustic background noise. Our study thus pinpoints a shared ventral premotor substrate for real-life speech production and perception with its basic properties.”
That is not what I have described. What I have said is
I do not claim that speech recognition involves only articulatory perceptions. No one denies that auditory perceptions are involved, least of all these people at Haskins, the lab that invented sound spectrograms and has contributed a huge proportion of the work in acoustic phonetics and speech synthesis. A fundamental problem is that the acoustic data are not sufficient alone. The relationship between recognized words and discernable features in the acoustic signal is too disorderly.
- Fowler & Rosenblum 1989), The perception of phonetic gestures, Haskins Laboratories Status Report on Speech Research 1989, SR-99/100, 102-117.
This is why successful speech recognition systems must employ elaborate statistical processing to take into account wider context of probabilistic data. An exclusively auditory account of speech perception is defective. Likewise an exclusively articulatory account is defective. The two are complementary aspects of a comprehensive account, and always have been, from the very beginnings of the study of phonetics. ‘The motor theory of speech perception’ is only controversial when (as that name implies) it is taken to be the complete account exclusive of auditory perception. That appears to be the sense in which you are taking it.
Another way to state what I have said is that we use the same systems to perceive words as we use to produce words. This should hardly be controversial. For negative-feedback control it is necessary to perceive what one is producing, and control keeps those perceptions in conformity with what one intends to produce. Production of observable effects and perception of those effects are complementary aspects of control in producing words. To deny that both auditory perceptions and articulatory perceptions enter the input functions for perceiving words, whether in our own speech or words from another source, would require special explanation. When we perceive another’s words, the articulatory perceptions are copies of reference signals for articulatory control, reference signals issuing from the word-perceiving systems. This is supported by the Iljina et al. reference above, for example. The location of the source of the words does not require us to switch from one set of control loops to another.
The motor theory of speech production was initially presented as an alternative to the prevailing acoustic assumptions. It is now more generally recognized that they are complementary.
https://www.semanticscholar.org/paper/The-Complementary-Roles-of-Auditory-and-Motor-in-a-Laurent-Barnaud/a5a083ad3a393291893f28a0b48b5d467e7417f0
How they are complementary is shown by the PCT analysis of experimental work by Katseff and Houde which I have presented in the Handbook and in several other places, e.g. at Stanford in 2012.

“After” is an important word in that statement. Once the speaker hears the sounds of a word it is too late to change the articulatory gestures by which those sounds are produced. Technically, of course, the speaker’s controlling of the sounds is continuous, but only with delay and in repetitions over time because the only means of controlling the sound is by changing the reference values for controlling articulatory perceptions, and by the time auditory feedback arrives the articulatory gesture has already had its effect and the articulatory organs have moved on in the control of subsequent perceptions.
The relationship is indicated in this PCT block diagram (from the Handbook and elsewhere):
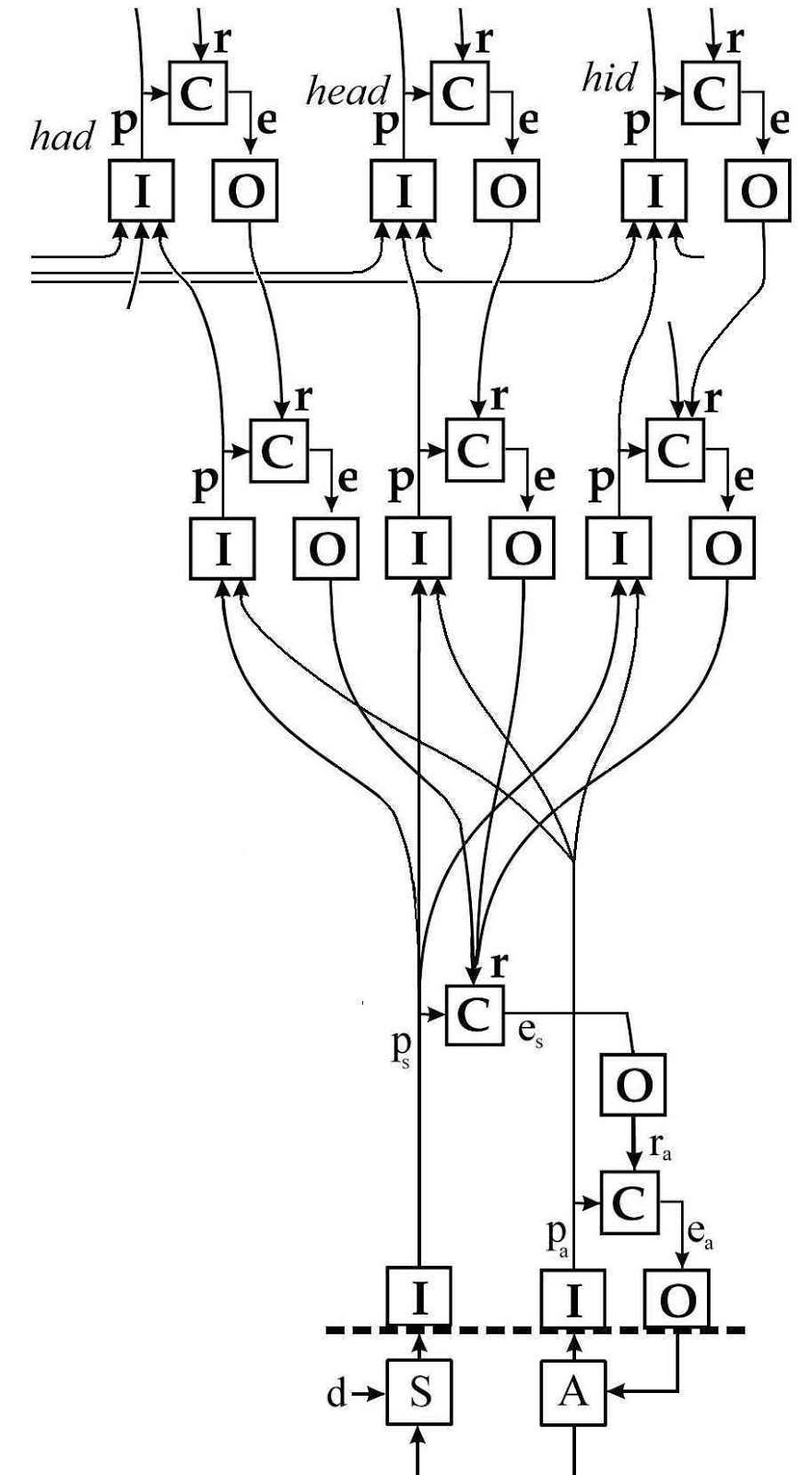
The lowest loop controls articulatory perceptions pa (subscript a for ‘articulation’). Its references are set by a loop that controls auditory perceptions ps (subscript s for ‘sound’). The auditory loop cannot directly control perceptions of words in real time.
The lower, articulatory loop is the output function for the auditory loop. However, it is not at a lower level of the perceptual hierarchy. They are complementary control loops in parallel sensory modalities. Indeed, each loop engages several levels of the perceptual hierarchy which are covertly represented by the lowest I and O boxes in the diagram. There is no way to control the sounds of one’s words except by controlling the tensions, pressures, and perhaps organ configurations of articulating one’s words
Acoustic features that differentiate words are transient, and by the time they are perceived the articulatory organs that produced them have moved on. The formant transitions that differentiate one consonant from another are about 50 msec long. In general, the speaker cannot correct a mispronunciation in mid utterance, but can only repeat the intended word or syllable. The speaker maintains and adjusts the reference values for articulatory perceptions over series of pronunciations of words that have in common the given combination of acoustic and articulatory perceptions.
Both auditory and articulatory perceptions are among the inputs to the perceptual input functions for words (at the top of this diagram). The claim is that this same arrangement of control systems controls perceptions of words spoken by others. To claim otherwise, as you appear to do, seems to claim either that this model is incorrect, or that you posit two distinct arrangements of control loops, this one for self-perception while speaking and an exclusively auditory system for perception of words spoken by others. Acoustic data are insufficient and Ockham beckons.
Of course you control your perception of the other person’s perception of what you have told them. How can you deny this? Why say “Yes, glad you agree” or “No, you misunderstood me”? Why repeat in different words when they don’t ‘get it’? Why argue except as attempting to change their perception of what you have told them so as to integrate it into their accepted understanding of the matter (as you perceive it)?
To perceive whether or not the other person has heard the intended word we’re not limited to remembering the word that we intended and that we heard ourselves say, and imagining that they have heard the same word. Whatever the recipient says and does can be input to a perception that they have or have not heard what we intended them to hear. Perceptual input that the recipient heard the intended word may not return immediately. There are many controlled perceptions for which feedback through the environment is delayed.
During the course of speaking the person who wants to be heard correctly speaks distinctly so that the intended word is distinct from other words that the recipient might perceive in the auditory input. Mumbled input results in perceptual signals for different words being more nearly the same. To say that two words are distinct is just another way of saying that they contrast. The proposed system of flip-flops is a way that control systems can bring about the appearance of contrast. If you have a different way of modeling categorial distinctions it will do the same.
Word perception is categorial. The possible values of the perceptual signal produced by the perceptual input function for a word are binary, yes it is that word, no it is not that word. What is variable is the strength of the signal produced by the perceptual input function for that word. The given inputs go to the perceptual input functions for many words. In the proposal for categorial perception that I have assumed, a system of flip-flops interconnecting the them identifies one of them, a categorial choice.
In the strict conditions of the pair test, there are only two possible words, so those are the two values of the perceptual variable “word the speaker intends me to hear”. In ordinary use of language there are almost always more than two possible values. In the pair test a disturbance is a greater or lesser amount of a selected phonetic feature that has the effect of decreasing the strength of the perceptual signal for the intended word and/or increasing the strength of the perceptual signal for a word other than the intended word. If the participant says it is not a repetition of the intended word then you know that the disturbance was effective.
Now I have restated the description of the pair test in different words as means of controlling my perception that you have not understood it (evidenced by your statements and questions) and as an effort to control my perception of you understanding it.
Then you are distinguishing between ‘the acoustical signals’ and the ‘speech sound’. The former is phonetic and can be measured instrumentally. The second is a phonemic perception by a language user who has developed the appropriate perceptual input functions. This phonemic perception can be identified, localized, and specified in terms of lower-level perceptions by some form of the Test to identify controlled perceptions. In a science of language the Test takes the form of the substitution tests of descriptive linguistics. For phonology such tests are epitomized or in ideal form in the pair test.
Eh. It’s not why they call them words, but I’m glad you acknowledge a perception called contrast, that you perceive the contrast for example between lane and rain, and that you perceive that contrast to be located at the beginnings of these words as represented alphabetically by l vs. r. The letters specify the locations of contrast and abbreviate them. The letter l represents the contrast of lane with Dane, bane, gain, etc. as well as with rain, and the letter r represents the contrast with all of those words as well as with lane.
Each letter represents a location at which a number of contrasts intersect. An alphabetic representation is convenient as a writing system for representing words, but it does not represent the contrasts well. For any language, it is possible to specify the contrasts in terms of presence or absence of a given feature of sound or articulation or in some cases both. There have been numerous attempts to specify a set of features that serves for every possible language. Trubetzkoy in the 1930s, Gunnar Fant in the 1950s-70s, Ladefoged, Matisoff, others. Chomsky’s philosophy has demanded that there must be a ‘universal alphabet of phonological features’. Here’s a recent table espoused by the LSA:
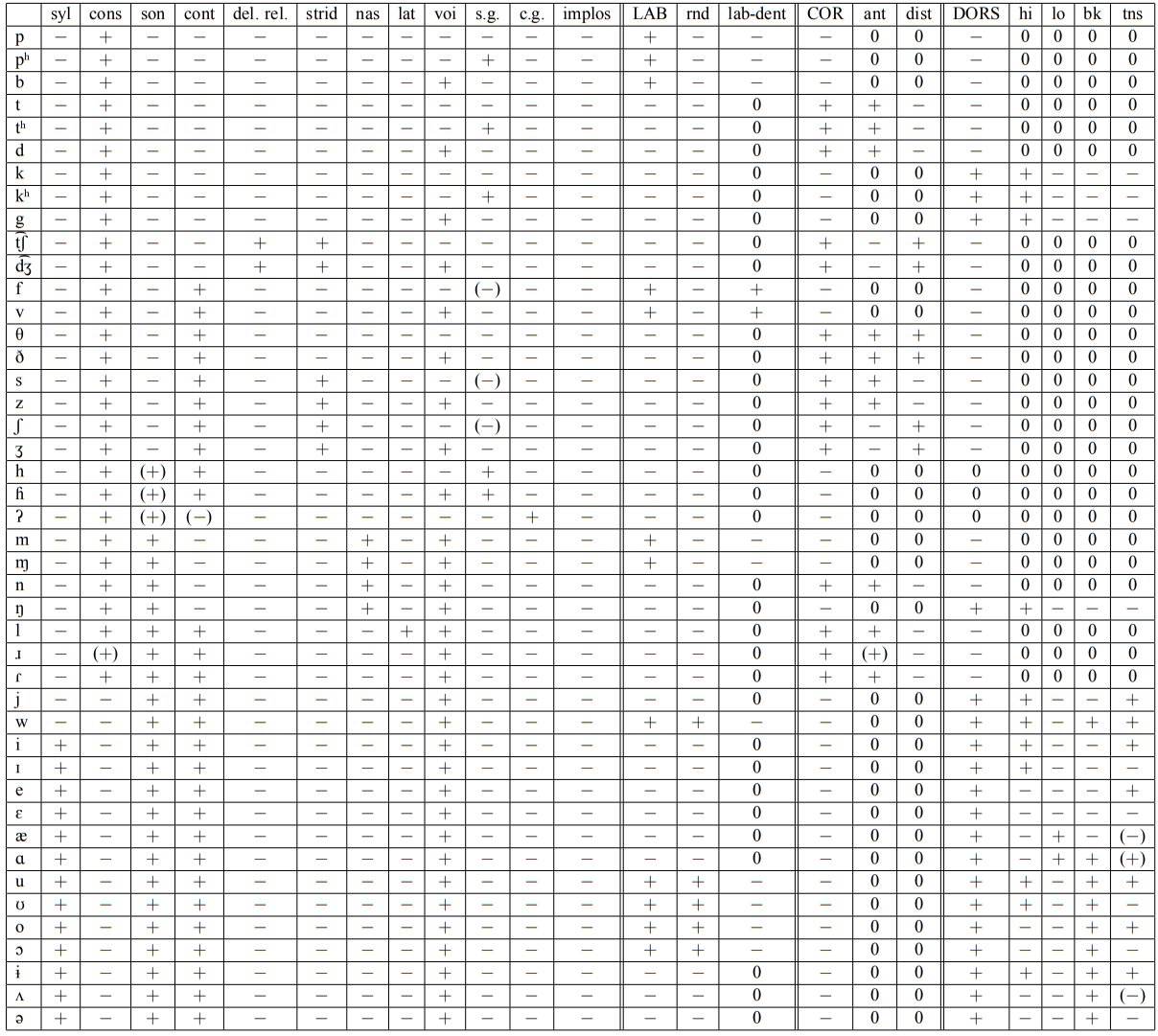
Each segment represented alphabetically is considered a combination of values (in the rows of the table) of the features listed in the column heads of the table. Definitions in terms of sound or articulation or often both are attempted in the linked document. These are not always easy to specify as perceptual variables. The syl (syllabic) feature and its contrast with the cons feature may be a function of relative amplitude, for example, but the picture is not clear cut. Labels are sometimes used beyond their definition, as e.g. pharyngeal and RTR (retracted tongue root), both of which in some languages at least are side effects of projecting the epiglottis into the air stream above the larynx. The epiglottis is an active articulatory organ in some languages around the world, one of a number of facts that are inconvenient for such schemes of proposed language universals.
Researchers at Haskins describe phonological contrasts in terms of actions or gestures specified in terms of perceptible intended targets (culminations of gestures) which are not always fully attained. They do not construe these as open-loop ‘emitted behaviors’ or the like, and a straightforward restatement in PCT terminology as controlled perceptions is transparently evident. They’ve done some nice modeling.
- Browman & Goldstein (1989), Articulatory gestures as phonological units, Haskins Laboratories Status Report on Speech Research 1989, SR-99/100, 69-101.
- Browman & Goldstein (1992), Articulatory Phonology: An Overview, Haskin’s Laboratories Status Report on Speech Research 1992, SR-111/112.23-42
- Gestural Model: Introduction to Articulatory Phonology and the Gestural Computational Model
Gestural Model | Haskins Laboratories
Contextual inputs to word recognition are many and diverse, as discussed here, in CSGnet posts, in B:CP, and elsewhere.
You’re not responding to the claim that we control articulatory perceptions in imagination, you’re just ignoring it. I have cited evidence above for this claim.
Segmental phonemes represented by letters are probably a descriptive convenience of linguistics (and of anybody else who wants an alphabetic writing system). They are not the only way that linguists represent the phonemic contrasts between words. The controlled perceptions by which we make the flip-flop flip to this word or flop to that word are probably both articulatory and acoustic, exploiting the way that these modalities are physically coupled in the environment, but only the articulation is directly controllable for whole syllables or words unless you s l o o w w w t h h e e e m m m w a a a a y y d o u w w n. These perceptions occur concurrently, but their durations do not neatly align with the boundaries asserted by an alphabetic representation and the control of each can be and often is a disturbance to concurrent, next, or prior ‘phonetic’ perceptions, which is just fine so long as the flip-flops pick the right winner.
The flip-flop mechanism, by the way, accounts for the old ‘pandemonium’ idea.
Rounding this back up to the topic, the substitution tests of linguistics are a way of identifying controlled variables. They are an application of the Test for Controlled Variables to the data of language. In the last few posts we’ve drilled down into the identification of syllables and words and the control processes for keeping them distinct from one another in socially institutionalized ways so that recipient can reliably perceive the words that the speaker intends them to perceive. The same methodology of substitution tests applies to other controlled variables that constitute language, as sketched in earlier posts in this topic, and elsewhere.