The main goal of research based on Perceptual Control Theory (PCT) – and what distinguishes such research from all other behavioral research based on Control Theory – is to find out what perceptual variables organisms are controlling when they are behaving. The main theoretical proposition of PCT is that the behavior of organisms in general, and humans in particular, involves the control a hierarchy of different types of perceptual variables. The hypothetical types are described in Powers’ book “Behavior: The control of perception” (B:CP).
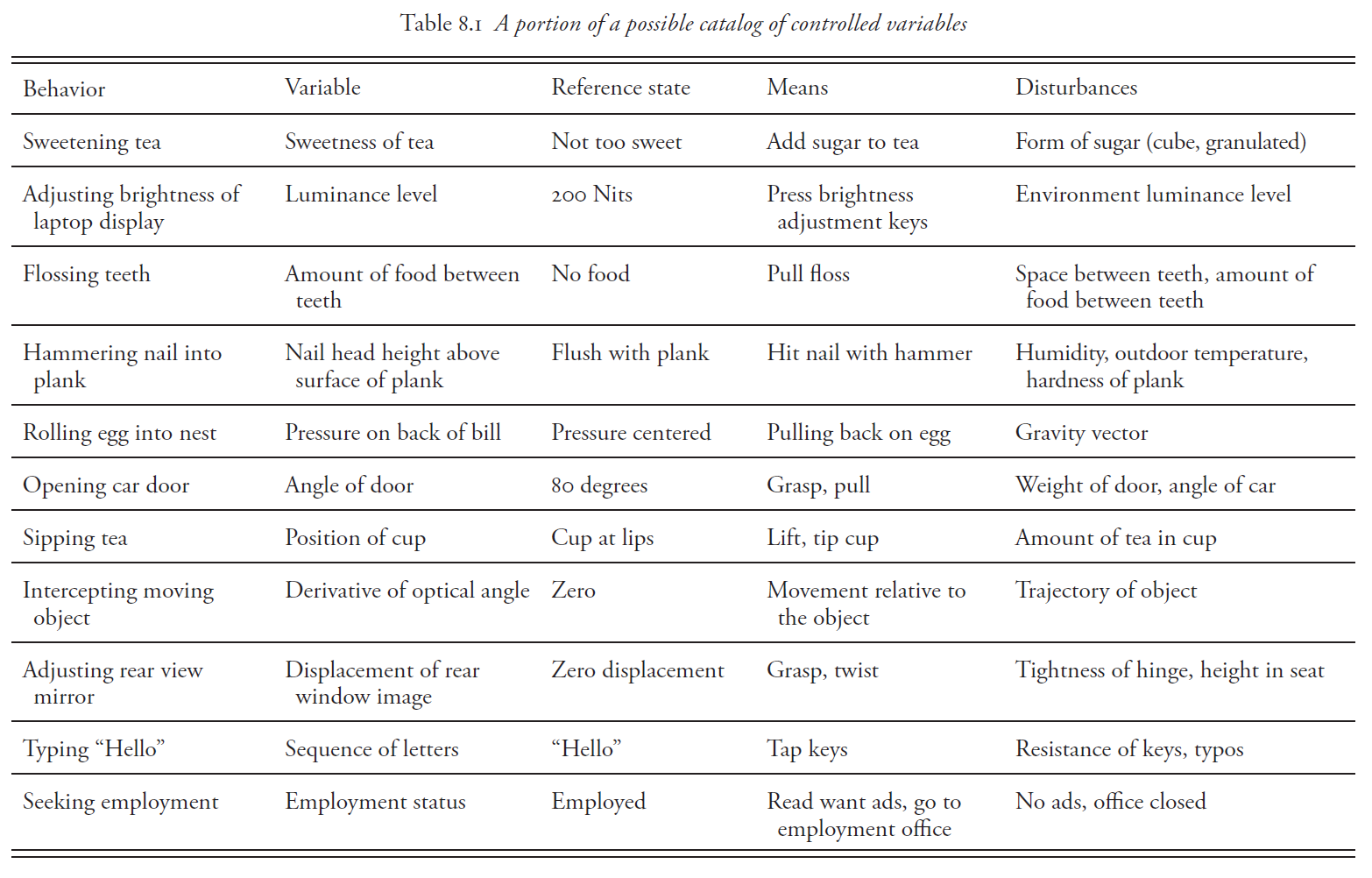
In order to test this hypothesis it is necessary to start collecting many different examples of the variables organisms control using some version of the test for the controlled variable (TCV). The result would be a database of controlled variables that might look something like Table 8.1 in my book “The Study of Living Control Systems”. In order for such a database to be useful, controlled variables should be described in a way that makes it possible to objectively determine their type – objectively in the sense that the description provides a rational basis for agreement that different controlled variables are of the same type.
All the controlled variables in Table 8.1 are described verbally. Such descriptions are unlikely to provide a good basis for an objective classification of these variables by type. A mathematical description of controlled variables would probably provide the best basis for an objective classification. But there are very few examples of research aimed at providing accurate mathematical descriptions of controlled variables. I’ve done some of this research but the variables described were pretty simple, such as position (x), distance (x1-x2), angle (arcsin[x1-x2)/(y1-y2)]), area (xy), perimeter (2[x+y]), and optical velocity (d[angle]/dt).
I think it’s important to figure out how more complex controlled variables can be described precisely – mathematically if possible; for example, how to give a precise definition of a variable like “Employment Status” at the bottom of Table 8.1. But in thinking about this problem I realized that it is unnecessary to define a controlled variable in terms of the physical “reality” to which it corresponds. A precise, mathematical description of a controlled variable need only describe that variable in terms of the variables of which it is composed. And both the controlled variable and the variables of which it is composed will be perceptual variables.
We do this already with some of the simplest controlled variables that we have studied. For example, the controlled variable in the compensatory tracking task is a perceptual variable that is defined mathematically as a difference between variables: target position - cursor position. We can think of target and cursor position as being physical variables but, in fact, they are perceptual variables themselves.
So I think the solution to finding mathematical descriptions of complex controlled variables is to develop mathematical descriptions of those variables in terms of the perceptual variables of which they are composed, variables that are themselves expressed mathematically in terms of the perceptual variables of which they are composed.
Because we can describe controlled variables solely in terms of perceptual variables, we can understand the perceptual basis of behavior without knowing how controlled perceptual variables relate
to reality. This means that the question of how well controlled perceptions correspond to reality is really irrelevant to a PCT understanding of behavior. In particular, it means that when we observe poor control it is never because there is a poor correspondence between between the variable being controlled – which is always a perception – and the reality represented by that perception. From a PCT perspective, when we observe poor control it is because the agent is not controlling or is unable to control the perceptual variable we think they are (or should be) controlling. This fact is illustrated in my “Just Following Instructions” demo.
Anyway, I would appreciate any ideas people have about how to usefully describe controlled variables so that these descriptions could be used as a basis for classifying controlled variables by type, the goal being to see if the types found correspond to those hypothesized by Powers in B:CP and other places.
This is the main goal because measures of environmental variables affecting controlled perceptions are the fundamental data of PCT. [You said “all other behavioral research based on Control Theory”, but the distinction is not limited to CT research, correct?]
For reference, here is your Table 8.1 from that book:
For a perceptual variable to be described mathematically, must it first be quantified?
No. As an illustration of treating complex perceptual variables as mathematical objects, consider the book Mathematical structures of language. (At that page is a link to download a PDF image of the book.)
The methodology to develop mathematical descriptions of complex controlled language variables employs the Test for Controlled Variables to identify perceptual variables as mathematical objects “in terms of the perceptual variables of which they are composed, variables that are themselves expressed mathematically in terms of the perceptual variables of which they are composed.” Obviously, there is a foundation of elementary data—there is no infinite regress into the imperceptible—but in the case of language these primitive data are themselves perceptual data.
The mathematics is from set theory and some linear algebra for mappings from subset to subset. Quantification can be brought in to the specification of data, e.g. the amount of difference in formant frequencies for segments of utterances which speakers perceive as contrasting (phonemically distinct), or some measure of the acceptability-rankings of homomorphous sentences, but such quantification is not essential; affirmations of perception suffice.
You identify the main goal (identifying what perceptions are controlled) and the main hypothesis (control cascades in a perceptual hierarchy). You do not mention the third principal distinction of PCT from other theories, which is a shame because it is one in which you have excelled: the construction of generative simulations which replicate observed behavior with fidelity that is unattainable by other theories of behavior.
It is for that purpose that quantified data have been seen as compulsory. Indeed, Bill, Dag, and others have emphasized that PCT is a ‘hard science’ like physics and chemistry because the PCT model is a quantitative model. But the higher we investigate in perceptual hierarchy, into complex perceptions which are of more general human interest and make for better PR and funding, quantification is more and more difficult.
What do we seek to quantify? PCT postulates neural signals, rates of firing in neurons which in principle can be measured (though they be averages across bundles of neurons); it postulates that these neural signals undergo amplification, damping, addition, subtraction, and other transformations between different parts of the nervous system; that they are transformed by ‘effectors’ into endocrine excretions, muscular efforts, and other physical effects in the body and in its environment; that sensory organs transform these effects in the internal and external environment back into neural signals entering the hierarchy at its lowest level, closing many concurrent control loops. In the theoretical model, all of these variables are quantities. In principal, all of these quantities can be measured.
So far, most PCT simulations (generative models of particular behavior) have been based on quantitative measurements of behavioral effects in the outer environment (efforts), environmental effects on sensors (stimuli) or as a surrogate measurements of environmental conditions detected by measuring instruments and determined by the Test to correspond to values of the controlled perceptual variable. Control loops that are closed through the interior corporeal environment are less accessible and have been much neglected in PCT
Precise quantification is not always necessary. In the CROWD demo, it does not matter precisely what the reference values for proximity to the ‘attractive’ agent and to fellow crowd members may be, only that these are controlled perceptions at some (moderate) reference level. The formation of rings and arcs is seen as a side effect of control, but in the wild it can also be a controlled perception as well (raconteur: “Gather round and hear my tale!”; teacher: “Circle time, children!”; policeman: “Disperse!”; participant: “Hm, people are gathered around her. Excuse me, can I squeeze in here?”).
The perceptual variables that constitute a language are not quantitative. The basic data, phonemic contrasts, may be thought of as categorial and the terms of their differentiation may be quantified along dimensions of their differentiation in several concurrent sensory modalities: for the articulation of speech, a combination of tactile and kinesthetic perceptions (from stretch and tension sensors), and auditory perceptions for the sounds of one’s own speech (always compared with that of others). There is a ‘quantal’ theory of speech (due to Ken Stevens, see here, here, and here) but the burden of it is not that speech sounds are quantities but rather that auditory perceptions are easier to control in certain parts of the acoustic space in which speech sounds are distinguished, that tactile and kinesthetic perceptions are easier to control in certain parts of the articulatory space in which speech organs differentiate them. This helps to explain that languages universally ‘prefer’ certain points of articulation and certain acoustic features (with a ranking of preference) despite that each of these is a location on indefinitely variable parameters.
People do not go around controlling individual phonemes. Even in the exceptional case where a syllable consists of a single phoneme (Mmmm!) it is an utterance that is controlled to be recognizably distinct from other possible utterances (Oooh! Ah! Eh!). The fundamental data of language are controlled perceptions of differences. Quantitatively, the degree of differentiation can drop even to nil if for other reasons no other word could occur in the linguistic and environmental context, and it is frequently the case that the given word is understood as present in the utterance even though not physically spoken (or written). An example is the noun which is the subject of the verb spoken and of the verb written in the preceding sentence. So this is another way in which the degree to which a given element of language contrasts to all other possible such elements in that position in the utterance is a controlled perception; as indeed is the perception of ‘such elements’ (elements of the same kind) and the perception of a position in an utterance with respect to its structure of kinds of elements in certain relationships. It comes down to relationships of dependency between words of different kinds (the kinds defined as requiring co-presence of a word or words of specified kinds) and the reductions due mostly to omitting overt expression of words whose presence can be reliably construed from context, but sometimes also socially institutionalized in arbitrary and historically contingent ways.
So the perceptions that constitute language are a quintessential example of collectively controlled perceptual variables; that is, people who use a given language control perceptions of correlation between the language perceptions that they control, and their reference values, with those which they perceive as being controlled by other users of that language.
A certain imprecision of control of the speech sounds one produces is a consequence of necessarily being unable to hear those sounds until it is too late to correct them, and the means of correction being the adjustment of reference values for tactile and kinesthetic perceptions which, at least consciously, feel rather vague and imprecise. This contributes to the great variability of observed and quantifiable acoustic outputs and articulatory targets and efforts toward them, variability which nonetheless is good enough for speaker and hearer to agree as to what words were spoken (sometimes with repetition).
Agreement as to the association of non-language perceptions with those utterances is another matter. Associative memory seems not to be a control process, though the establishment, strengthening or weakening, and above all the purposeful reconstruction of memory probably involves control processes of the midbrain. Bill’s concepts of a Category Level and his actual example in B:CP of what he considered Program Control (looking for his glasses in places that came to mind from memory as he moved around the room) involve this murky area that has been rather neglected in PCT.
In the above table and proposed database, perceptions at successively higher levels increasingly are controlled through environmental feedback paths which include features which are socially stabilized, or are themselves collectively controlled as in the case of language. This is only to acknowledge that we live in a built environment, that what is built must be maintained, and that humans rather than natural processes control the maintenance of human constructs. Collectively controlled perceptions are the invisible water in which we cosseted swim. The table and database must accommodate this.
Employment status seems like a binary variable, employed or not. Maybe a better cv is work satisfaction or expected work satisfaction, and the employment status can change depending on the error.
If the cv is always a sum of the disturbances and own efforts, maybe ‘work satisfaction control’ can be modelled with a system that tries to counteract the actions of the employer by own actions. Some of the terms come from just the employer (salary), and others come from just the employee (effort), and some may be combined.
So, let’s say the employer lowers the salary, or doesn’t give the expected raise. This might result in direct protests for the raise; or in people slacking off. Or maybe the employer does not give a raise, but gives public honors to some people, or they get some kind of promotion, and they don’t protest. Maybe if they do get a raise, they also feel obliged to work longer hours. I don’t know, I’m talking out of my ass here. There is a vast literature on work satisfaction, might be worth looking into.
I think that the fundamental data of PCT – the data needed to test the model – are the controlled variables themselves. The measures of environmental variables you are talking about must be the disturbances used when testing for controlled variables. These measures (which are themselves perceptions) are either explicitly or implicitly included in reports of the results of PCT research. But the main result that is relevant to a PCT understanding of the behavior is the controlled variable, which is the observed variable – presumed to be a function of environmental variables – that is found to be protected from these disturbances; it is the variable that is being controlled.
Yes. Research aimed at identifying the variables around which behavior is organized distinguishes PCT-based research from all other behavioral research. I specifically referred to non-PCT control theory approaches to behavioral research since, like PCT, they are based on control theory but, unlike PCT, don’t understand that behavior itself is a control process organized around the control of a hierarchy of many different types of controlled variables.
I’ll take a look at the book but maybe you could give me an example of a mathematical (maybe a better way is to call it a “formal”) representation of a higher level variable controlled when speaking.
Could you give an example of a set theory or linear algebra-based representation of some relatively complex linguistic controlled variable?
“Quantify” is probably the wrong word. What I want to do is figure out a way to formally describe controlled variables – the different variables that have been found (in various research studies) to be those that are being controlled when organisms are carrying out various behaviors. The variables should be described in a way that allows them to be classified into different types using some formal methodology, such as cluster analyses.
Formal will do. If you can put aspects of language into mathematical structures (as per the title of the Zellig Harris tract that you sent) then that is “quantitative” enough for me.
That may be, but the fundamental data of a PCT understanding of language is controlled variables.
The rest of your post isn’t really relevant to my interests, but thanks for sharing.
I don’t think there is anything wrong with a possible controlled variable being binary; indeed, the highest level variables in my three level spreadsheet hierarchy model are binary (logical variables that can be only true or false). But I agree that it’s a little difficult to imagine how this would be implemented in a nervous system with what are essentially continuously varying (and somewhat noisy) neural firing rates.
But I like your proposed continuously variable alternative:
This does illustrate one of the points I was making about defining controlled variables; it can be done in terms of lower order perceptual variables. In this case, two of those lower order variables – salary and free time – can be defined pretty precisely. The variable work_relationships presents a bit more of a problem, although the verbal definition certainly suggests its possible type (relationship). Maybe there are verbal ways to name controlled variables that would be a reasonable basis for typing them.
I think these are very good suggestions about how work satisfaction might be defined and controlled. They certainly suggest ways to test whether work satisfaction, as so defined, is indeed a controlled variable. And it might even be possible to find existing research in that vast literature on work satisfaction that could be a basis for model based tests to determine whether work satisfaction, as defined, is, indeed, a controlled variable. And could, then be entered into the database of controlled variables that Bill suggested building.
But, then, how do we describe work satisfaction in the database in a way that would make it possible to determine what type of variable it might be?
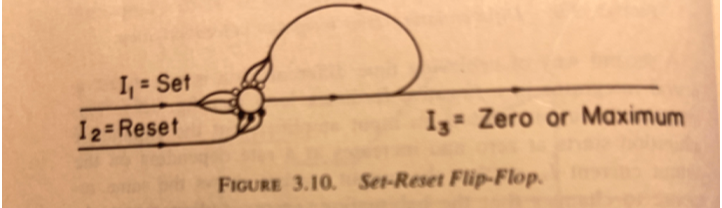
In analog computing the structure that does this is called a flip-flop. The connections of the electronic circuit have a straightforward analogs with inhibitory and excitatory synapses. It has been extensively discussed here since the first decade of CSGnet. A good explanation is here, including properties of combinations of interconnected flip-flops. (Caveat: understanding of these elaborations has advanced greatly since 1997.)
The basic flip-flop is the means by which continuously variable streams of electrons through conductive metal wires become the discrete zeroes and ones of binary computer code and digital computing. It transforms the analog into the digital. It is the fundamental unit of memory store in a digital computer. It enables computation of a next state of the stored variable based upon not just the current input but also upon all prior states of that variable — in automata theory, the mechanism of sequential logic as distinct from combinational logic, which lacks memory and is dependent only on current input. (These are also distinct from the informal logic that is familiar as a human thinking process, or its more disciplined form as propositional logic.) Analog computers thus can do digital computation while retaining computation with continuously varying values as well.
As to ‘work satisfaction’ in my experience the employer’s satisfaction with the work is more important in a ‘buyer’s market’ and the employee’s satisfaction is more important in a ‘seller’s market’ (in the labor market, where the employee’s ability to perform is the ‘commodity’). Obviously, these are different complex perceptions, with different sets of lower-level perceptual inputs for the employer and for the employee. The crux is that the employee can quit or be fired, depending.
But this is kind of getting off topic – at least the one I am interested in – which is how to describe controlled variables so that these descriptions can be used as the basis for determining whether different controlled variables fall into classes – types – that are like those hypothesized in B:CP.
This seems like one of the most, if not the most, important thing to test about PCT – and it seems to have been what Powers thought people should be doing to test the model, but little or no work has been done along these lines. So maybe it’s not that important. If not, I’d like to know why not. But if it seems important to some others here then I’d appreciate any thoughts you have about how to determine whether the controlled variables found via testing are of the types predicted by the PCT model.
I don’t know how general can we go and still have the math apply to all potential controlled variables. For now, in the cases I’ve studied, it seems we can say that the controlled variable is going to be a sum of the effect of behavior and the effect of the disturbance. A mathematical description of a controlled variable should start with defining how a specific measure of behavior of the participant can affect the controlled variable, and how a specific measure of experimenter’s behavior can affect the controlled variable.
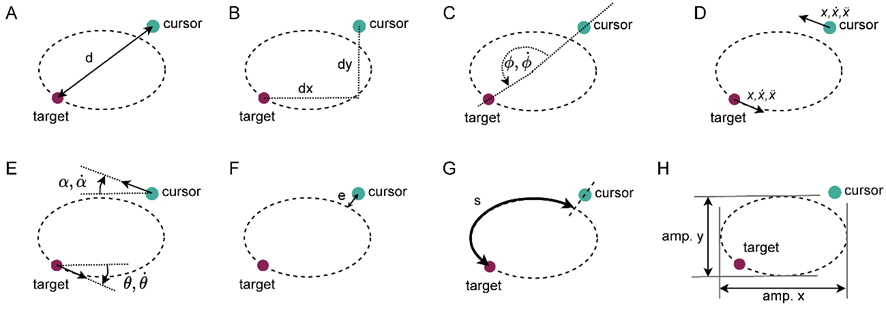
As example, here is a figure from a paper I’m writing:
These are some possible different geometric and kinematic variables that can be visually perceived by a participant following a target that is moving along an elliptic trajectory. Some of them can be discarded from the start - the Euclidean distance (A) is always positive, there is no way of using it in a simple proportional-output control loop. The other ones all need to be defined as:
qi = F(target position) - F(cursor position) = qd - qf
Conceptually, qd and qf are not perceptual variables from a lower level, they are environmental variables defined by the experimenter in order to make the estimate of the controlled variable. They are not perceptual variables because only the controlled variable has a potential neural correlate (perceptual signal), while the other two, qd and qf, don’t.
The function F defines the effect of the cursor or target on the qi, and in this case is the same function. For example, in (C), F is the unwrapped angle from the cursor or target, to the center of the ellipse, and to the x axis. It is important that it is unwrapped (it doesn’t reset at 2 pi), because then the difference between qd and qf will show the angular difference between the cursor and the target. Another example (H) the amplitude of the target can be measured independently of the amplitude of the cursor, and their difference is the cv; or (G), the arc-length should be measured from the same point, so that the difference of the arc-length of the cursor and the target gives a useful measure of cv.
When the variables are defined like that, they are always going to have the same units, so there is always a way to find relative stability between qd and qi, by comparing their variances. There is also always a correlation between qd and qi.
Ideally (when the cv is a good approximation of the one used by the participant), fitting a model to the qi, qd and qf defined as above would return consistent delays.
To answer your question - the way to determine if the variables fit the types proposed by BCP is to first make sure we found good approximations of controlled variables, then see if the delays of variables proposed to be “higher” also have larger delays, and the ones proposed to be “lower” have lower delays. The same types should have the same delays, and hopefully be conceptually similar.
I’m basing this on Bill’s Spadeworks paper mostly. It seems it might apply to higher-order variables, but hard to say without experiments.
Since controlled perceptions of contrasts are controlled perceptions they are not only the fundamental data of linguistics they are also among the fundamental data of PCT. What exactly are you denying here?
I have laid out examples in many places. A relatively early example is in the Festschrift for Bill. How the simpler aspects are reached—contrastive phonemic segments and/or features, syllables and prosody, morphemes, morpheme classes, words, word classes, constructions of words and morphemes specified in terms of form classes—is amply shown in a century of literature on theory and practice of descriptive linguistics as it has developed, not including the neo-phrenology and ‘innate language organ’ hand-waving by some philosophers. Mappings among sets of sentences and phrases (constructions) are reached by a formal methodology testing controlled perceptions such as relative acceptability, or acceptability in like contexts, but that is because of the notorious instability and limited accessibility of judgments of meaning (mapping of sentences and phrases to non-language perceptions to which they ‘refer’, which they ‘denote’, ‘connote’, etc.) and of paraphrase (a judgement that such a ‘semantic’ relation for one utterance is the same as that for another). And all of this is presented in compact form in Mathematical structures of language, in A theory of language and information: A mathematical approach, and in many other writings such as those on this site. But none of this is of any interest to you, I take you at your word:
If it doesn’t interest you, then don’t pretend to ask. These waters are not for dipping thimbles.
These are collectively controlled variables. If you still believe that collective control only results from conflict, that could be an impediment. Without collective control all one has left for an account of language is something like Chomsky’s innate ideas and Pinker’s ‘language instinct’.
I am denying that “contrasts” are the only perceptual variables controlled in language. Indeed, I’m not convinced that what linguists call “contrasts” are even controlled variables.
I wish you could just post, here in discourse, one example of a formal description of a linguistic controlled variable.
I’m interested in seeing if there is a formal way of describing controlled variables. Whether these variables are “collectively controlled” (whatever that means) or not has nothing to do with my interest in developing a formal way of describing controlled variables that can be used as the basis for seeing if those variables can be sorted into types that correspond to those proposed in B:CP.
Yes, this is one way to classify controlled variables. I’ve developed a couple demos (here and here) to show how this might be done. The reaction time in my demos really only classifies the variables in terms of relative level in a presumed hierarchy. I doubt that reaction time (delays) can be used to classify controlled variables in terms of type, though.
Well, the definition of the variable gives you the type. A position, an amplitude, a category, a sequence, etc.
I don’t see other possibilities for classification - collect a bunch of good approximations of controlled variables, classify in terms of relative delays and see if the types of variables you assumed are on the same level (based on BCP) have the same delays.
Good. That would be a preposterous claim. I don’t know anyone who makes it.
That’s true, you aren’t. In its strictest form, the particular application of the Test is called the ‘pair test’, substituting one segment of sound/articulation for another in a short utterance and observing whether the difference disturbed a native speaker’s perception of hearing a repetition of the same utterance vs. hearing two different utterances. You were present at a demonstration that some differences that make a difference in English don’t make a difference in Swedish and vice versa. That demonstration hinged on substitution of one segment of sound/articulation for another in a short utterance. But to convince you is neither my business nor my need.
The history of attempts to generalize the methods and results of linguistics, ‘phonemes of culture’ and the like, strongly suggests that other social phenomena are not nearly as tightly structured as language. Indeed, language is instrumental in how people cooperate and conflict in perceiving and controlling such phenomena socially.
Here is an algebraic expression:
N t V
The algebraic variables N and V are form-class labels representing two sets of words, familiarly named “nouns” and “verbs”, respectively, and t is a smaller set of morphemes (a few words and a few affixes on V) that we interpret as tense and aspect. As each term represents a set of words, the formula represents a set of sentences, and the sequence of form classes is a sentence-form representing a set of sentences that all have the same form. A plate broke is an example. (The ‘indefinite article’ a is an automatic complement of the subclass of N called ‘count nouns’, a detail that need not detain us here.)
N t be V-en is another sentence-form stipulating the same form-classes, with the addition of two algebraic constants, be and -en. A plate was broken is an example.
Users of English perceive differences in the acceptability of these sentences as sentences, or differences in the contexts in which they are acceptable. A fish swam, my head swam, and vacuum swam differ in these ways, as do A plate broke, dawn broke, and vacuum broke.
When the satisfiers of the sentence-form N t V and the satisfiers of the sentence-form N t be V-en are ranked as to their perceived acceptabilities, or contextual constraints on acceptability (there are various ways to do this), a perceived difference between two satisfiers of one is not reversed between the corresponding (same word-choices) satisfiers of the other. Thus, A plate was broken, dawn was broken, and vacuum was broken. (The lower acceptability of dawn was broken discloses its basis in metaphor. The vacuum was broken has normal acceptability in suitable context. An account of what is involved in metaphor and in the ‘definite article’ would require you to learn things that do not interest you.)
Such perceptions of ‘normalcy’, or of relative acceptability, or of context that is required for an utterance to be an acceptable sentence, when tested in this way, provide a criterion for a mapping from one set of sentences to the other, an operation in linear algebra. A mapping (also called a transformation) is a correspondence between the correlated members of two sets preserving some property.
Careful investigation discloses between N t V and N t be V-en an intervening sentence-form N is in the state of one Ving it. (Independently, but not coincidentally, investigation of the history of English discloses that the en suffix was at an earlier stage a noun roughly translated ‘state’ or ‘condition’.) In general, the set of transformations takes the shape of a network of elementary sentence-differences. The significance and ramifications of that finding are out of scope here.
Nothing here but perceptions, and nothing of stimulus-response, conditioning, or linear causation in the investigation of them. The methodology of disturbance by substitution tests identifies controlled variables, beginning with the fundamental data of contrast, controlled perceptions which establish discrete, socially pre-set elements in the continua of speech as conventional means of identifying what words were spoken despite myriad disturbances. The application of representations and tools of set theory and linear algebra enables the investigation of the enormous and superficially disorderly body of language data to be orderly and systematic, and provides ways of representing and communicating findings.
Many investigators have done much to identify socially conventionalized gestures and postures. (Birdwhistell, Goffman and others come to mind, and the work on micro-expressions.) To control these consciously in order to employ the methodology of substitution tests would require the disciplines and practices of an actor.
Alas, I have not been able to identify a monograph that I read in the early 1970s, in which students in (as I recall) a Speech Department (?) gained proficient control of aspects of speech production such as nasality, degree of pitch variation and amplitude variation, breathiness, something they called ‘orotundity’, etc. They made a series of recordings (male and female voices) reading a neutral passage called ‘the Rainbow Trail’ (referring to the Grand Canyon), substituting different values of these parameters in different combinations. Listeners were then asked to assess the character and personality traits of what they perceived as different men and women reading that passage. There was close agreement in their assessments.
That is an example of applying the methods developed in linguistics to other social phenomena. However, it does not extend to establishing elements as combinations of simpler elements (morphemes as combinations of phonemes), form-classes of elements, regular combinations of form-classes, mappings among such combinations. It is possible that some existing research into non-language social phenomena can be restated in such terms. Maybe someone has tried. I don’t know.
What variable do you think this shows to be controlled?
But this demonstration says nothing about controlling contrasts. It just shows that, when a person is asked to control for correctly saying whether two speech sounds are the same or different, speakers of different languages often base their responses on different features of the same acoustical waveforms. This is not a Test to determine the variables people are controlling when using language. You have to do the Test quite differently to see what the acoustical basis of these same/different decisions might be.
Of course it is!
All this was very interesting but I don’t see what it has to do with determining the types of controlled variables used in language. But that’s OK; Adam already answered my question. There is no need for formal descriptions of controlled variables; just plain old verbal descriptions will do. And these can be checked by seeing whether the variables we call the same thing are actually the same type by looking at speed of corrective response to a disturbance.
Nope. It’s a judgement whether one utterance is a repetition of the other. The ‘acoustical waveforms’ can and do vary greatly, as in e.g. want to and wanna vs. wand two and Wanda (which are also variable), or nitrate vs. night rate.
These questions suggest that your attention is on the controlled phonetic variables which are the means of controlling the different kind of controlled perception to which I wish to draw your attention. For almost a century, that variable has been called contrast by those who have studied the matter. The quarrels among them have been about how to represent it segmentally (alphabetically) or by clusters of concurrent features, what those features are, how to represent their durations not coinciding neatly with alphabetic boundaries, and other such problems. These are problems of description, that is, how to specify the higher-level CVs, which are discrete, in terms of the lower, which are continuous. The variables of phonetics are continua, with distinct extremes which may be construed as centers, transitions which may be construed as boundaries, and other ‘cues’. The passage about the pair test that I quoted describes how the fundamental discrete controlled perceptual variables are established. In a symbolic representation of those discrete variables, it is easy to assume that e.g. ‘the phoneme’ t is a discrete entity with specific physically measurable content (the phonetic variables); but t is a representation of a contrast between what is occurring at that location and all the other possible occurrences at that location (within utterances in the language): t vs. p, t vs. n, and so on. The physically measurable phonetic ‘content’ is quite variable, so long as it suffices in the given context. In night rate instead of what one might have supposed obligatory to produce t, closure of the oral cavity by the tongue against the gingival ridge with a consequent pause in voicing, what often occurs is a pause in voicing by closure of the vocal folds with no movement of the tongue toward the gingival ridge. This alternative is not available for nitrate. Research into higher-level linguistic variables, event perceptions made of series of phonemes, the reduction of t to glottal stop can be described as a property of word boundary, one of various ‘cues’ for perceiving where one word ends and another begins.
When linguists use words like ‘cue’ it does not label them as behaviorists. All of this is explicitly a search for controlled perceptual variables, though of course the particular terminology of PCT can’t be expected in the literature of linguistics.
On occasion the words ‘stimulus’ and ‘response’ may occur in discussions of phonetic and phonemic (contrast) perception. In my experience such usage is uncommon and incidental, and when it does occur it is about recognition. When perceptual input is sufficient for a perceptual input function for perception π to generate a perceptual signal π, that perception-recognizing process can quite properly be called the response of that perceptual input function to the perceptual input. Such occasional phraseology does not deny the place of that input function within a loop and within the hierarchy. We know there is a linear cause-effect relation between any successive pair of functions in the path around a control loop. Perceptual recognition is a cause-effect stimulus-response process. To communicate to an investigator that perception π has been recognized, however, requires closing the loop and controlling π.
That’s what I said. The subject is asked to judge (and indicate by saying) whether the two utterances are the “same” or “different”. Presumably the subject is controlling for making the correct judgment, which means saying the right thing.
No, I would just like to know what controlled variable you think is revealed by this test. I don’t think this “pair test” can be used to tell what variables are controlled in speech. But it could be used to tell the variables controlled when people make judgements of whether or not there is a difference between speech sounds.
Yes, “contrast” is a reasonable description of the variable that must be controlled in the “pair test”. But a contrast between what? Linguists see the contrasts that are the basis of the same/difference judgements as differences in how the speech samples are produced: voiced vs unvoiced, labial versus non-labial, etc. But these contrasts can’t be perceived in the pair test so the basis of these judgements must be an acoustical contrast. There are probably studies that have tried to determine what this is for different speech sounds. Such studies would tell us the acoustical basis of same/different judgements but it wouldn’t necessarily tell us what variables are actually controlled when people speak.
Yes, indeed. Which is why it has been so difficult to develop speech recognition systems. But those systems have come a hell of a long way since I first met them in the 1970s.
I think linguists have made brilliant observations. But they certainly didn’t understand speech as control of perception. And the problem isn’t just a matter of terminology. So linguists haven’t really done any testing or modeling that is of much use to PCT.
But there are examples of research done by linguists – psycholinguists, I guess – that are much closer to being tests for the controlled variables than is the pair test. One example is that paper you sent to me where the researchers put what was basically an adjustable filter into the feedback function between vocal output and heard input so that the speaker would have to adjust their output to compensate for the disturbance created by the filter if, in fact, what was being disturbed by variation in the filter setting was an aspect of the acoustical signal that was being controlled. There were problems with their methodology – it wasn’t really a proper test for the controlled variable – but it was definitely on the right track.
And Labov’s data describing the geographical differences in the distribution of the pronunciation of different diphthongs provided a good basis for PCT based modeling. So there is some useful data in the linguistics research literature, but there could be much more if some of those researchers were willing to learn PCT.
Nope. What you said was “a person is asked to control for correctly saying whether two speech sounds are the same or different”. An utterance is made of plural speech sounds, with few exceptions (mmm, ah, sss, and the like) which are inconsequential to this important distinction. ‘Speech sounds’ refers to the phonetic level of language structure and ‘contrast’ refers to the higher phonemic level of language structure.
The word ‘judgement’ is ambiguous. The perception can be called a judgement and the statement can be called a judgement. Better then to say the subject is asked to perceive (and indicate by saying) whether the two utterances are the “same” or “different”. This is a perception of contrast. If they do not contrast they are repetitions of the same utterance (despite ineffective differences); if they contrast they are different utterances. The contrasts can be localized to one or more points at corresponding places within the utterances. If they are a ‘minimal pair’ there is only one point of contrast in the continua of speech, and that is the ideal situation sought for the pair test.
The usual methodology in the field is less formal. The speaker says yét aaq̓o (the name of Mt. Shasta). The linguist asks “is that aak̓o or aaq̓o?”, exaggerating the fricative release. (This is done by forcing air past the oral closure by raising the larynx while the vocal folds are still closed for the laryngealized stop, which increases air pressure behind the oral closure. The release is normally lenis or inaudible.). The pitch of the friction sound is higher for k̓ and lower for q̓. In this example, one utterance is a word and the other is a combination of nonsense syllables that could be a word in the language but isn’t.
Variables at different levels are controlled in speech. The acoustic perceptions are probably what you are thinking are exclusively “the variables that are controlled in speech”. Articulatory variables have traditionally been represented by phoneticians in terms of places of greatest occlusion of airflow through the oral cavity. For PCT, this is a surrogate for tactile and kinesthetic perceptions that the speaker and listener (in imagination) are controlling. I have described elsewhere the relation between these two modalities, error in auditory feedback being corrigible only by adjusting the references for articulatory control over successive repetitions. You referred to the experimental work that I have brought to your attention.
That is in fact what I have told you it is used for. Correction: Such substitution tests are used used to locate the contrasts between utterances, and to identify phonetic features occurring at the locations of contrast. The pair test is an idealization of substitution tests (like aak̓o vs. aaq̓o) at a level of language above phonetics, the level of phonemic contrast. These substitution tests identify what we call phonemic contrasts. For these we can devise symbols called phonemes, a convenient alphabetic way of representing speech. Despite appearances and our alphabetic training and prejudices the k̓ and q̓ etc. are not ‘things’. The q̓ indicates a position (specified relative to other phonemes in the written sequence) at which k̓, k, q, p, p̓, t, t̓, m, and all the other possible phonemes are not occurring. The perceptual signal constructed by the input function for q̓ is strong, and the signals from the input functions for all the alternative phonemes are weaker to varying degrees. The phonetic means are variable by which q̓ is differentiated from each of these others, differing most obviously between any pair. The phonetic ‘differences that make a difference’ between k̓ and q̓ are not the same as the differentia of k and q̓, p̓ and q̓, and so on. And no single phonetic feature or bundle of features is always present when a contrast of q̓ with all other possible phonemes is perceived. It is not possible to guarantee for each phoneme that some particular measurable phonetic perceptions always characterize it in every context of its occurrence or even in every production of the same utterance. Contrasts between utterances cannot be built up from phonetic differences between utterances. “Today’s speech recognition systems use powerful and complicated statistical modeling systems.” In this way, they take context into account.
Visual perceptions (lip-reading) also contribute to the phonemic perceptual input functions, and the McGurk effect shows that this visual input can result in hearing a different phoneme. In another way, if context supports an expectation of hearing or reading a given word the recipient may understand that word in that context rather than what was actually produced. Psychologists reversing the meaning of ‘behavior is the control of perception’ is an example that is familiar to you.
More generally, language has hierarchical structure, of which the phonetic and the phonemic are the lowest levels, but the levels in that structure are not levels in the perceptual hierarchy. With syllables and words we are already at the Event level. (An essential difference between syllables and words is that, except for their intersection in the set of monosyllabic words, syllables are nonsense utterances.)
Obviously, the elements of language which are so structured are perceived in the ordinary way within the perceptual hierarchy. The structuring itself is a human artifact, subject to certain universal constraints which are described in the works cited but otherwise maintained in the course of social use.
So I am correct in what I said because an utterance is a type of speech sound.
I think you are missing the point I am trying to make, which is that the “pair task” is, like all tasks, a control task. In the pair task a person is asked to control for the relationship between what they say (“same” or “different”) and whether the components of the pair are perceived as same and different. The person doing the task is asked to keep that perception in a reference state of “correct”.
A nice exercise would be to identify the disturbance(s), outputs and likely controlled variable in this task. Then I think you will get a better idea of how this “pairs task” relates to an actual test for controlled variables and what the results of this task can tell you about the variables controlled in speech.
Yes, and an even better way to say it is that the subject is asked to control for producing the correct relationship between what they say (“same” versus “different”) and what they perceive about the pairs (same versus different). I think it’s useful to try to see behavior – all behavior, including that in conventional psychological experiments – as control, which it always is!
Not at all. I am thinking of variables that range from the phonemic to the semantic to the pragmatic and beyond. I think some great hints about what these are and how to identify them are to be found in Pinker’s marvelous book The Sense of Style.
I’ll just end by saying that that only people I have ever seen who control for “contrasts” in speech are linguists. And they do it when they do the “pairs” and “substitution” tests.