Good point. And there’s a nice description in B:CP of how this might be implemented with neural currents in the nervous system. It’s in Figure 3.10:
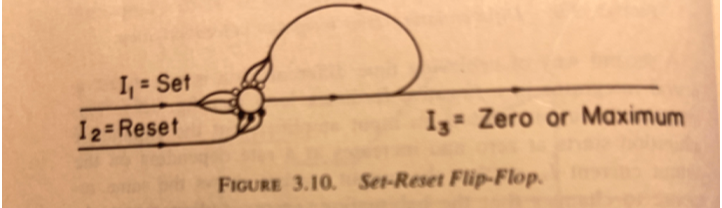
But this is kind of getting off topic – at least the one I am interested in – which is how to describe controlled variables so that these descriptions can be used as the basis for determining whether different controlled variables fall into classes – types – that are like those hypothesized in B:CP.
This seems like one of the most, if not the most, important thing to test about PCT – and it seems to have been what Powers thought people should be doing to test the model, but little or no work has been done along these lines. So maybe it’s not that important. If not, I’d like to know why not. But if it seems important to some others here then I’d appreciate any thoughts you have about how to determine whether the controlled variables found via testing are of the types predicted by the PCT model.
Best, Rick