The pair test (not ‘task’) is indeed a test to identify controlled variables, and as always with the Test the investigator is also controlling perceptual variables in order to introduce disturbances to a posited CV, so I am not missing that point.
The pair test does not concern what the native speaker participant says. The participant can be completely silent (the yes/no indication of repetition can be nonverbal). The pair test requires the participant to control whether what they hear is the same utterance in the language as what they just previously heard.
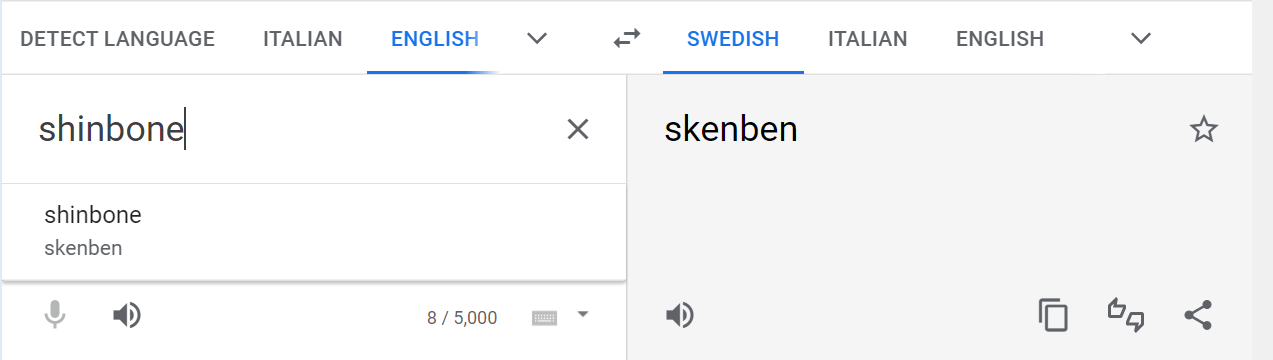
The pair test does not concern whether “the components of the pair” are the same or different. The ‘components’ of utterance A can be quite different from those of utterance B, and B is still perceived as a repetition of A. If you go to translate.google.com, set up the left side for English with the input word shinbone, and the right side for Swedish, The word skenben is the output word. This is what it looks like:
Below the printed word skenben is an audio widget to hear its native pronunciation [šíənbíən]. Go ahead and listen to it on the translate.google.com page. As I demonstrated with Christine Forssell at one of our conferences, an American pronunciation as [šíínbíín] is a repetition of the same word for a speaker of Swedish, although the pronunciation is foreign. The difference between the long vowel ii and the diphthong íə is a phonetic difference that doesn’t make a phonemic difference in Swedish.
The setup is that the native speaker is hearing utterance A followed by similar utterance B. A disturbance is the substitution in B of a phonetically different feature of pronunciation. The output is the participant’s indication (verbal or otherwise) that B is or is not a repetition of A. We are looking for a difference that makes a difference, a disturbance to the perception of repetition (same word).
When we look for a phonetic difference that makes a phonemic difference, the data do not present a simple linear mapping from phonetic detail to phoneme. A variety of phonetic distinctions can suffice to make a given phonemic contrast. A given phoneme representing a point of contrast can be identified with a variety of phonetic features.
At a given point of contrast (represented by a letter or ‘phoneme’), one phonetic feature distinguishes that point from one phoneme or set of phonemes, and a different phonetic feature distinguishes it from another possible phoneme or set of phonemes. The contrast between b and p is ideally associated with the length of delay (the prolongation of silence) before onset of voicing after that segment; the contrast between b and m is in the presence of a perhaps random noise perceived as nasality as voicing continues throughout; the contrast between b and d and between m and n is in the transition of formant frequencies from whatever was the preceding vowel and to whatever vowel follows; and so forth. But these cues, too, may be attenuated, lost, or overridden depending on context and on other variables the speaker may be controlling. That is why speech recognition systems have to resort to statistical processing that takes context into account. There may be structural limitations on the full generality of these features or parameters of contrast, as e.g. the neutralization of the voicing contrast in b/p etc. after s. There is no contrast between spoon and sboon, and the spoonerism on ‘spaghetti’ is ‘skabetti’, not ‘sgapetti’.
A different kind of ‘task’ would be to ask whether pronunciation A of a given utterance in the language is the same as pronunciation B of the same utterance (a repetition of it). Discriminating whether the phonetic ‘components’ are the same or different is completely different from the pair test because when you are discriminating phonetic differences it is a given that utterance B is a repetition of utterance A. Either it is a repetition, or the subject asks “why are you asking me if they’re pronounced differently? Of course they are, they’re different words.” (Yes, yes, we can provide for homophones.) In this kind of task, you can’t ask whether or not it is a repetition, you can only talk about an imitation which is more or less accurate phonetically. In this kind of phonetic discrimination task it is fruitless to ask whether A is “the same as” B because two pronunciations of the same word are never phonetically identical. There are just too many physical variables, and perception at that level of detail is imperfect.
But in the pair test the subject ignores phonetic differences that don’t make a phonemic difference. The question is not how good is the imitation, it is whether or not it is a repetition of the same word or words. (Or a repetition of the same nonsense syllable or syllables that phonologically could be a word in the language but happens not to be.)
The repetition can be in a different dialect of the language, or in a different register (e.g. degree of formality), such that the phonetic data are quite different, but the recipient still recognizes utterance B as a repetition of utterance A. So the American visitor talks about a bruise on her “sheenbeen” [šíínbíín] and her Swedish host says yes, I heard you hit your skenben [šíənbíən] on my coffee table when you went for a drink of water in the dark. In Swedish, that phonetic distinction does not make a phonemic contrast. It’s a difference that doesn’t make a difference in Swedish, but it does make a difference in English, e.g. in the contrast between Korean and careen, Achean and achene, and so on.
To use the words of a language for various purposes the speaker and hearer control the phonemic contrasts between words by varying the references for controlling a variety of phonetic distinctions. It is a commonplace of PCT to control a perception by varying the references for a number of other perceptions.
The issues have been deeply studied for more than a century in ways that are quite compatible with PCT, and there is a huge body of data. It’s perfectly understandable that you are unfamiliar with this, it’s not your field.
The test for the controlled variable begins with a hypothesis about the variable the agent is controlling when performing a particular task. What is the hypothesis about the variable being controlled in the pair test?
I agree. As I understand it, all the pair test is concerned with is how well people can correctly identify the pairs as the same or different.
OK, so the hypothesized controlled variable is that sameness judgements are based on phonetic features of pronunciation in utterance A and B.
Of course, there are a variety of phonetic (acoustic) patterns that are heard as the same phoneme. So there will be many different phonetic versions of, say, /l/ that distinguish it from the many different phonetic versions of /r/, if this phonemic difference is made in a language (as it is not in Japanese). But I don’t understand why you are always talking about contrasts. When I hear the words lane and rain, for example, I don’t hear a “contrast” between /l/ and /r/. When I hear the word lane I hear it starting with the /l/ sound; not with a sound that contrasts with the /r/ sound. So I don’t understand what this “contrast” thing is that you think is an important aspect of language understanding.
These are all features of the acoustical signals that are the basis for identifying the different phonemes. They provide the basis for discriminating (contrasting) one phoneme from another but that’s just because we can identify each on based on it’s acoustical features. With all the cool technology that is now available for varying the acoustical signal in real time it should be possible to do a proper version of the test to get a more detailed and accurate picture of the acoustical variables that are controlled when speaking.
Yes, but it’s also a commonplace of PCT that we can only control what we can perceive. And when I am speaking I can only perceive the phonemes I am producing (controlling); I can’t perceive the phonemes that are presumed to “contrast” with those phonemes.
I think linguists have made some great observations. But I don’t see their explanations of these observations as being in any way compatible with PCT, the motor theory of speech perception being a particularly clear example of this incompatibility.
PCT provides a way to understand how the brains of speakers and hearers might do this with flip-flop structures connecting input functions for words. If the perceptual input function for word A receives more and stronger inputs than those for words B, C, …, then A is the word that is perceived. The inputs for word recognition are not all acoustic. There is evidence that some inputs are articulatory as the hearer controls the pronunciation of the heard sounds in imagination. Other inputs are visual if the hearer can see the speaker’s face (cf. the McGurk effect). Importantly, other inputs are contextual, both in what has been said and environmentally. I talk about this in my chapter in the Handbook.
The perception of contrast by the linguist (I grant you that) is necessary for doing linguistics, because the phonetic means of keeping words distinct from one another are variable in diverse ways and change over time, and because to do any linguistics beyond phonology requires a relatively simplified representation (usually alphabetic) of the differences that make a difference. Imagine, if you can, the problem of representing utterances in a language for which there is no existing writing system. This is the circumstance in which the methodology of descriptive linguistics was developed, mostly in the 20th century. Much of this was motivated and funded by colonial administrators, by missionaries eager to translate the Bible and preach, and by organizations like the CIA. As in many other fields including psychology, sociology, anthropology, and yes physics, chemistry, and medicine, workers drawn to the intrinsic interest of a science of language have found ways to sustain and build the field in this fundamentally duplicitous world. To do any linguistics beyond phonology requires a set of phonemic symbols and rules for their mappings to phonetic continua such that a writer/transcriber can represent any utterance in the language and a reader can produce from such representation a repetition (not an imitation) of the original utterance. Because the phonetic means of keeping words distinct from one another are variable in diverse ways and change over time, the contrasts between words are the primary data of linguistics. This does not necessarily mean that the speakers and hearers of the language control perceptions of contrast.
Conversely, it is not at all clear that there must be perceptual input functions for phonemes. The shortest thing that can be pronounced is a syllable. (Mmm! is a syllable, usually beginning with a glottal stop.) There are perceptual input functions for syllables, some of which are also perceived as words. Words are sequences of syllables. The phonetic constituency of syllables in a given language is constrained partly by physics, physiology, and the relation of articulatory gesture to acoustic consequences and auditory perception, and partly by historically contingent conventions of the language community.
But syllabaries are unwieldy for all but the phonologically most simple languages, with simple syllable structures. For good methodological reasons, including the comparability of different languages, the linguist needs an alphabetic representation of syllables and words.
There are three ‘agents’ in the pair test. One is the speaker (who may be represented by a recording). The second is the listener or subject. Your question is addressed to the third agent, the experimenter, who formulates and controls the hypothesis in respect to the other two agents. The hypothesis is that the listener, for each successive utterance heard, is controlling to perceive which of two words the speaker intends him to hear.
In ordinary language usage, many of the utterances spoken and heard, are ambiguous, sometimes multiply ambiguous. They are
produced by overlapping continua of articulatory gestures, and heard as overlapping continua of phonetic perceptions.
The speaker controls the articulatory perceptions and hears their acoustic consequences only after the sound has escaped control, and imagines what the recipient has heard. The speaker controls these perceptions as means of controlling perceptions of the intended syllables and words, and of course the syllables and words are means of controlling yet other perceptions.
The hearer controls both auditory perceptions and (in imagination) perceptions of the articulatory gestures that they would have to make in order to produce those auditory perceptions. These together are among the diverse inputs to systems for controlling syllables and words. Perceptions of syllables are inputs primarily (but not exclusively) to input functions for controlling words, and higher levels of control are engaged just as in the speaker.
By these means, the speaker is controlling perceptions of the hearer perceiving the words that the speaker intends them to hear, and the hearer is controlling perceptions of perceiving the words that the speaker intends them to hear. (They are also controlling at those higher levels.)
The pair test and other substitution tests are part of the experimental methodology of linguistics. Its purpose is to establish a writing system with which any utterance in the language can be recoverably represented; that is, given a written representation of any utterance, a reader can repeat that utterance and a hearer will perceive that as a repetition of the same utterance. Not an imitation of the same pronunciation of that utterance, a repetition in which any differences of pronunciation do not make any difference (except perhaps to mark the speaker as a foreigner, or the like). For this purpose, the data of contrast are primary because the data of how the contrasts are effected are not at all a simple mapping from characteristic phonetic features to phoneme and vice versa.
In the pair test, the experimental setup artificially limits the possibilities to two words which differ only at one point of contrast. The artificial limitations of the experimental setup are perceptions controlled by the experimenter, the linguist.
The experimenter has selected a pair of words with phonetic differences between them at one point in the continua of speech, and little or no difference on either side of that point. It is at that point of contrast that the experimenter modulates one or another controllable phonetic perceptual variable. This varying of the values of phonetic perceptions at the identified location of contrast between the two words is another kind of perception that the experimenter (linguist) is controlling in the pair test or any less rigorous phonemic substitution test.
Singling these phonetic perceptions out and varying them arbitrarily almost always requires training in phonetics. With few exceptions a person without such training cannot perceive and control them separately, but only in synchrony with one another according to the phonemic patterning of the language they are speaking—more, presently about this.)
Now we get back to the experimenter’s hypothesis. The experimenter’s hypothesis is that modulating a specified phonetic perceptual variable is a means of controlling a perception of one word or the other—that a difference in the value of that phonetic variable makes a phonemic difference within the context presented by this pair of words—and since the phonetic variable is a continuous variable an experimental question is what are the ranges of variability for perceiving one word vs. for perceiving the other. Because of priming and for other reasons these ranges overlap.
OK, this current execution of the Test demonstrates that the speaker and hearer control polar values of the identified phonetic perceptual variable in one pair of words—the delay of voicing, let’s say, that distinguishes dibber from dipper.
[Note: English speakers generally cannot perceive that the b here is not fully voiced, i.e. that there is a cessation of voicing while the lips are closed. One of my teachers, Leigh Lisker, did ground-breaking work on this, a review article 50 years later is here, and a chapter by him is in a book that I edited in 2000.]
[Note: This feature is the length of time that a perceptible phonetic variable, voicing, is not present between the bundle of phonetic variables that is represented by an alphabetic symbol such as b or p and the bundle of phonetic variables that is represented by the alphabetic symbol for a vowel such as i.]
This polarity of values of that phonetic variable (voicing delay) does not occur in isolation. Polarities of other identified phonetic variables co-occur with it at that same point of contrast, with values that do not differ appreciably from one to the other of that particular experimental pair of words. However, keeping the value of the voicing delay variable constant and changing the value of one of the other variables results in perception of a different word, e.g., dipper vs. dicker, or dibber vs. digger. The contrast between dicker and digger again is effected by controlling the delay in voicing exactly as that between dipper and dibber. The essence of structuralism is to perceive polarities organized into matrices.
[Note: Changing the value of a phonetic variable from one pole to the other may result in perception of an utterance that could be a word in the language but happens not to be, e.g. starting with dibble vs. dipple and changing the preceding tongue gesture and formant contours for the vowel results in dibol vs. dipole. It is in these unutilized spaces of possible words that marketers look for trade names. Dibol is now the name of a pain-relieving medication. Does the hearer in a pair test know this? It doesn’t matter. It’s not a repetition of dipole.]
By repeated execution of the pair test (or less formal substitution tests, or by keeping track of phonetic differences discernable to her trained ear systematically across the vocabulary) the experimenter (the linguist) establishes that in other utterances the same polarity of values of that phonetic variable (voicing delay) coincides with other identified polarities of phonetic variables coincident with it or neighboring it.
A conventional alphabetic representation as e.g. t vs. d, c vs. j, k vs. g facilitates a cataloging of the allophones (phonetic variants) of each phoneme and the environments (neighboring phonemes) in which each variant occurs. This form of representation has been a staple of descriptive linguistics for a century or more, and has lent itself to the convenient descriptive fiction that this alphabetic entity, the phoneme, is a ‘thing’ with diverse phonetic realizations. The fraught inquiries into the reality of the phoneme in the 1940s and '50s, and beginning in 1959 and the '60s the polemics of Chomsky & Halle and their students against it and in favor of a ‘universal alphabet of distinctive features’ coocurring in ‘bundles’, point to the fragility of this convenient fiction, but because of its convenience and our training in alphabetic literacy it seems unlikely ever to go away. Even the Generative™ phonologists after Chomsky & Halle still write alphabetically what they analyze as feature matrices with feature lengths conveniently fitting within segmental boundaries (and elaborate rules for feature spread, etc.). In PCT work, however, we need to un-fool ourselves and be clear about the perceptual variables involved, and the continua of speech are not alphabetical or conveniently demarcated into segments. The peaks and transitions of one phonetic perceptual variable in general do not neatly coincide with those of co-occurring phonetic perceptual variables.
When we distinguish bidder from bitter (in American English) the voice-delay variable has dwindling or no consequence in ordinary speech. The feature that cues the contrast instead is in the length of the preceding vowel. This is more clearly heard with the diphthong in rider vs. writer.
When you say the pairs are the same or different, do you mean that sameness judgements are “based on phonetic features of pronunciation” in the two words? That is, if they are “the same” do you mean that one is an imitation of the pronunciation of the other, with minimal phonetic differences? If so, you do not agree. If you mean the second word is a repetition of the first word regardless of differences of pronunciation (differences that don’t make any difference), then you do agree. Which is it?
(The source of the quoted phrase is below.)
Yes, at the lower level of this control process the speaker controls the values of the phonetic perceptions as means of controlling the hearer’s perception of the intended word in contrast to other possible words. The hearer controls the perceived value of the given phonetic variable in relation to an imagined perception of (= the reference value for controlling) the polar opposite value of that variable in the system of contrasts (represented by polarities of values of phonetic variables) for the given language.
[Note: The particular polarity of values isolated in a test of one minimal pair may be irrelevant to the contrast of the same pair of phonemes in a different pair of words. The long effort by Bloch, Trager, Smith, and others to derive phonemes exclusively from phonetic detail turned out to be in vain and was justly excoriated by Chomsky et al. The primacy of controlling the contrastiveness of words by means of only partly consistent, variable, and changing control of articulatory and acoustic perceptual variables was unavailable to Noam because he would have to admit that his teacher and benefactor was right, and for whatever personal reasons that has been intolerable for him. Relevant detail here.]
You hear a contrast between lane and rain. The location of the contrast is at the beginning, before the amplitude peak. (As there is only one syllable, there is only one amplitude peak.) Other points of contrast are between lane and lamb, or rain and ram; between lane and laid, and so on. The speaker is controlling an (imagined) perception that you are perceiving the intended word. Because in this case a minimal pair is involved (contrasting at only one point), the speaker is doing so with high gain on control of those phonetic features which are most different at that point, with the result e.g. of lengthening their duration or increasing their audible intensity. But in a different context the gain on the speaker’s control of those features at that point is lower, and acoustical input is defective not only for that reason but also often due to various environmental disturbances, limitations of perception, and distracted attention. “In that big storm flotsam was pounding on the stanchions and the {lane|rain} dropped heavily on the girders beneath.” If the context is about homeless people sheltering under a bridge, it’s rain. If the context is damage to one traffic lane on the bridge, it’s lane.
The speaker in the normal case (outside the special circumstances of the pair test) controls the phonetic detail with lower gain correspondingly as context does more of the heavy lifting, but in all cases the speaker is controlling a perception that the hearer is perceiving the intended word in contrast to other possible words. That is what I mean by controlling contrast: it is a contrast between words, a perception which is controlled by means of controlling perceptions of phonetic differences at the points at which the words differ—whatever phonetic difference or differences suffice to make the phonemic difference (the contrast). If the hearer misunderstands the incorrect word, the speaker often repeats the intended word with high gain on the differentiating phonetic features at the specific points of contrast between the misheard word and the intended word. This neatly demonstrates control of contrast by means of differentiation of features which in a highly supportive context may be controlled with gain so low as not even to be discernible.
Just this morning my wife introduced me to our new neighbor and his lovely 7-year-old daughter. As I was approaching, I heard her name as Marissa, but they corrected me, she is Melissa. I may have been predisposed by her multiracial appearance to hear the less common name.
Betty Botter bought a bit of butter; “But,” she said, “this butter’s bitter! If I put it in my batter It will make my batter bitter. But a bit o’ better butter Will make my batter better.”
Then she bought a bit o’ butter Better than the bitter butter, Made her bitter batter better. So ’twas better Betty Botter Bought a bit o’ better butter.
This is called a nursery rhyme, but it is of no antiquity or folk origin.Poet and novelist Carolyn Wells wrote it in 1899. It is often also called a tongue twister. I have heard it used as an exercise in ‘correct’ pronunciation. In the most familiar dialects of American English, only the t of 'twas has the voiceless puff of air (aspiration) characteristic of the delayed voice onset feature, and the t of it and of the first occurrence of but (not the second) is typically a glottal stop, the sound heard in the exclamation of alarm 'uh-oh" and in the negation “uh-uh”, for which we have no alphabetic letter. The ts in every other place are pronounced as a flapped r which in such dialects occurs three times in use the latter ladder later. Just as in the case of bidder vs. bitter and rider vs. writer cited earlier, delayed voicing plays no role in any of these (in most dialects of American English).
Nevertheless, in a ‘pair test’ presenting two readings of this so-called ‘nursery rhyme’, one by a speaker of the Queen’s English and the other by a typical American, a hearer fluent in either variety of English would perceive the same words. Differently pronounced, but the same.
Systematic differences in features of the acoustic signals provide the basis for identifying the intended word, differences between the intended word and other possible words in the hearer’s memory and therefore in the hearer’s imagination when the perceptual input functions for those words concurrently receive input which is ‘correct’ except for the sounds at the point of contrast. The perceptual input signals generated by those other perceptual input functions are therefore weaker than that generated by the intended word.
The phonetic ‘content’ or ‘substance’ of a given phoneme can vary enormously, depending on its context relative to other phonemes in that word as well as on the usage context of the word and the kinds of environmental or psychological disturbances that the speaker may perceive to be effective upon the hearer’s ability to perceive the intended word. So no particular ‘acoustical signals’ are reliably ‘the basis’ for perceiving any given phoneme in all its occurrences.
No, we can’t identify each phoneme based solely on its acoustical features, not in all contexts of natural language use. It’s not for lack of trying with all our cool technology. It’s just that language is not alphabetical. It just isn’t. The burden of contrast can shift from one phonetic feature to another, and indeed that is the most usual path by which languages change, as they always and continuously do.
You are forgetting control of perceptions in imagination. You are forgetting that perceptual inputs go to many perceptual input functions concurrently. Input of dipper goes not only to the perceptual input function for the word dipper but also to the perceptual input functions for dicker, dinner, and many other words, naming here only a few of those that produce some amount of perceptual signal from that input.
What you have been saying indicates to me that you are not familiar with these explanations.
Let’s be sure we’re talking about the same thing here. In a nutshell, what is the motor theory of speech perception?
This is the motor theory of speech recognition. I would like to see the evidence for it. I don’t believe there is any.
Yes, this is a real phenomenon and it suggests that visible mouth movements are a component of the perception of speech when they are available.
OK, great.
Then how do you know there are phonemes?
This is a very poorly stated hypothesis about a controlled variable. According to this description the controlled variable is “which of two words the speaker intended him to hear”. What are the possible values of this variable? What is a disturbance to this variable? How do you know whether or not the disturbance was effective?
This is certainly not true if the speaker is controlling the acoustic consequences of those variations in articulation, as they certainly are unless they are deaf.
More motor theory of speech recognition. I know of no evidence that this is the case. Do you?
And I think this test has revealed interesting things about articulatory differences in the way different phonemes are pronounced. But now it’s time to move on and use the test for controlled variables to determine the acoustical variables that are being controlled by means of variations in articulation. I think linguists know quite bit about this but just can’t let go of their discovery of those easy to categorize articulatory “contrasts”, which would, indeed, be a nice basis for recognizing and discriminating phonemes if only they could be perceived by the hearer.
This is not a hypothesis about the variable controlled while speaking. But I agree that it is a method for determining the articulatory variables that distinguish one speech sound from another, which is a perfectly fine finding but it is not a finding regarding the variable(s) that speakers control when they produce speech sounds; nor is it a finding about the basis of the perception of these speech sounds by the hearer. It’s not about control yet…but it’s gettin’ there;-)
No, it does not demonstrate this; at least, not for the hearer (speakers do control articulatory movement as the means of controlling the acoustical consequences of those movements). In order to conclude that a variable is the basis for recognition of speech you have to show that it is perceived. It’s easy to show that most of the articulatory variations that produce speech cannot (and need not) be perceived by a hearer. For example, we can understand speech even when these articulations are actively concealed, as in ventriloquism.
Yes. this was a very interesting discovery.
Usually, these judgements can only be based on acoustical features of the two words. But if they are played along with a picture of a person speaking them (as in the McGurk effect) these judgements will be based on both acoustical and visual variables.
I think the subject says “same” if the acoustical signal is heard as being the same speech sound, even if the acoustical signals themselves are actually different.
You can influence another person’s perceptions but you sure can’t control them.
Of course. I hear a contrast between all words, except homophones, of course. That’s why they call them words; they are all different.
Well, I am rarely in contexts where visual variables are necessary or available. But they can certainly help.
But we are not talking about imagining that we are speaking or hearing; we are talking about really speaking and hearing.
The motor theory of speech perception is what you described above. Basically, it is the theory that we recognize speech by making and perceiving (in imagination or in actuality) the motor movements (vocal articulations) we would have to make to produce that speech.
Iljina, Derix, Kaur, Schulze-Bonhage, Auer1, Aertsen, & Ball (2018), Real-life speech production and perception have a shared premotor-cortical substrate.,
“Our fndings show that an electrostimulation-defned mouth motor region located in the superior ventral premotor cortex is consistently activated during both [production and perception] conditions. This region became active early relative to the onset of speech production and was recruited during speech perception regardless of acoustic background noise. Our study thus pinpoints a shared ventral premotor substrate for real-life speech production and perception with its basic properties.”
That is not what I have described. What I have said is
I do not claim that speech recognition involves only articulatory perceptions. No one denies that auditory perceptions are involved, least of all these people at Haskins, the lab that invented sound spectrograms and has contributed a huge proportion of the work in acoustic phonetics and speech synthesis. A fundamental problem is that the acoustic data are not sufficient alone. The relationship between recognized words and discernable features in the acoustic signal is too disorderly.
Fowler & Rosenblum 1989), The perception of phonetic gestures, Haskins Laboratories Status Report on Speech Research 1989, SR-99/100, 102-117.
This is why successful speech recognition systems must employ elaborate statistical processing to take into account wider context of probabilistic data. An exclusively auditory account of speech perception is defective. Likewise an exclusively articulatory account is defective. The two are complementary aspects of a comprehensive account, and always have been, from the very beginnings of the study of phonetics. ‘The motor theory of speech perception’ is only controversial when (as that name implies) it is taken to be the complete account exclusive of auditory perception. That appears to be the sense in which you are taking it.
Another way to state what I have said is that we use the same systems to perceive words as we use to produce words. This should hardly be controversial. For negative-feedback control it is necessary to perceive what one is producing, and control keeps those perceptions in conformity with what one intends to produce. Production of observable effects and perception of those effects are complementary aspects of control in producing words. To deny that both auditory perceptions and articulatory perceptions enter the input functions for perceiving words, whether in our own speech or words from another source, would require special explanation. When we perceive another’s words, the articulatory perceptions are copies of reference signals for articulatory control, reference signals issuing from the word-perceiving systems. This is supported by the Iljina et al. reference above, for example. The location of the source of the words does not require us to switch from one set of control loops to another.
“After” is an important word in that statement. Once the speaker hears the sounds of a word it is too late to change the articulatory gestures by which those sounds are produced. Technically, of course, the speaker’s controlling of the sounds is continuous, but only with delay and in repetitions over time because the only means of controlling the sound is by changing the reference values for controlling articulatory perceptions, and by the time auditory feedback arrives the articulatory gesture has already had its effect and the articulatory organs have moved on in the control of subsequent perceptions.
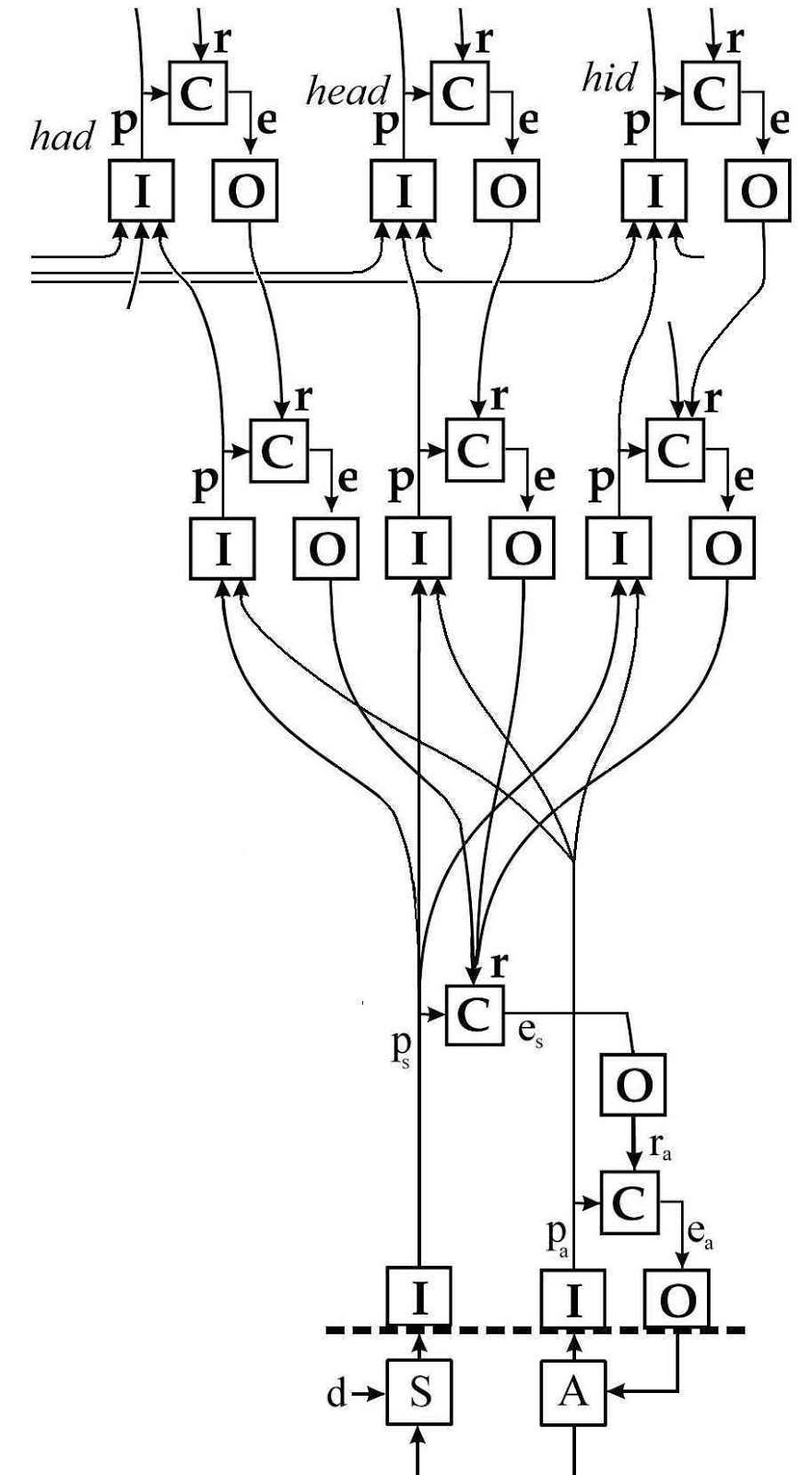
The relationship is indicated in this PCT block diagram (from the Handbook and elsewhere):
The lowest loop controls articulatory perceptions pa (subscript a for ‘articulation’). Its references are set by a loop that controls auditory perceptions ps (subscript s for ‘sound’). The auditory loop cannot directly control perceptions of words in real time.
The lower, articulatory loop is the output function for the auditory loop. However, it is not at a lower level of the perceptual hierarchy. They are complementary control loops in parallel sensory modalities. Indeed, each loop engages several levels of the perceptual hierarchy which are covertly represented by the lowest I and O boxes in the diagram. There is no way to control the sounds of one’s words except by controlling the tensions, pressures, and perhaps organ configurations of articulating one’s words
Acoustic features that differentiate words are transient, and by the time they are perceived the articulatory organs that produced them have moved on. The formant transitions that differentiate one consonant from another are about 50 msec long. In general, the speaker cannot correct a mispronunciation in mid utterance, but can only repeat the intended word or syllable. The speaker maintains and adjusts the reference values for articulatory perceptions over series of pronunciations of words that have in common the given combination of acoustic and articulatory perceptions.
Both auditory and articulatory perceptions are among the inputs to the perceptual input functions for words (at the top of this diagram). The claim is that this same arrangement of control systems controls perceptions of words spoken by others. To claim otherwise, as you appear to do, seems to claim either that this model is incorrect, or that you posit two distinct arrangements of control loops, this one for self-perception while speaking and an exclusively auditory system for perception of words spoken by others. Acoustic data are insufficient and Ockham beckons.
Of course you control your perception of the other person’s perception of what you have told them. How can you deny this? Why say “Yes, glad you agree” or “No, you misunderstood me”? Why repeat in different words when they don’t ‘get it’? Why argue except as attempting to change their perception of what you have told them so as to integrate it into their accepted understanding of the matter (as you perceive it)?
To perceive whether or not the other person has heard the intended word we’re not limited to remembering the word that we intended and that we heard ourselves say, and imagining that they have heard the same word. Whatever the recipient says and does can be input to a perception that they have or have not heard what we intended them to hear. Perceptual input that the recipient heard the intended word may not return immediately. There are many controlled perceptions for which feedback through the environment is delayed.
During the course of speaking the person who wants to be heard correctly speaks distinctly so that the intended word is distinct from other words that the recipient might perceive in the auditory input. Mumbled input results in perceptual signals for different words being more nearly the same. To say that two words are distinct is just another way of saying that they contrast. The proposed system of flip-flops is a way that control systems can bring about the appearance of contrast. If you have a different way of modeling categorial distinctions it will do the same.
Word perception is categorial. The possible values of the perceptual signal produced by the perceptual input function for a word are binary, yes it is that word, no it is not that word. What is variable is the strength of the signal produced by the perceptual input function for that word. The given inputs go to the perceptual input functions for many words. In the proposal for categorial perception that I have assumed, a system of flip-flops interconnecting the them identifies one of them, a categorial choice.
In the strict conditions of the pair test, there are only two possible words, so those are the two values of the perceptual variable “word the speaker intends me to hear”. In ordinary use of language there are almost always more than two possible values. In the pair test a disturbance is a greater or lesser amount of a selected phonetic feature that has the effect of decreasing the strength of the perceptual signal for the intended word and/or increasing the strength of the perceptual signal for a word other than the intended word. If the participant says it is not a repetition of the intended word then you know that the disturbance was effective.
Now I have restated the description of the pair test in different words as means of controlling my perception that you have not understood it (evidenced by your statements and questions) and as an effort to control my perception of you understanding it.
Then you are distinguishing between ‘the acoustical signals’ and the ‘speech sound’. The former is phonetic and can be measured instrumentally. The second is a phonemic perception by a language user who has developed the appropriate perceptual input functions. This phonemic perception can be identified, localized, and specified in terms of lower-level perceptions by some form of the Test to identify controlled perceptions. In a science of language the Test takes the form of the substitution tests of descriptive linguistics. For phonology such tests are epitomized or in ideal form in the pair test.
Eh. It’s not why they call them words, but I’m glad you acknowledge a perception called contrast, that you perceive the contrast for example between lane and rain, and that you perceive that contrast to be located at the beginnings of these words as represented alphabetically by l vs. r. The letters specify the locations of contrast and abbreviate them. The letter l represents the contrast of lane with Dane, bane, gain, etc. as well as with rain, and the letter r represents the contrast with all of those words as well as with lane.
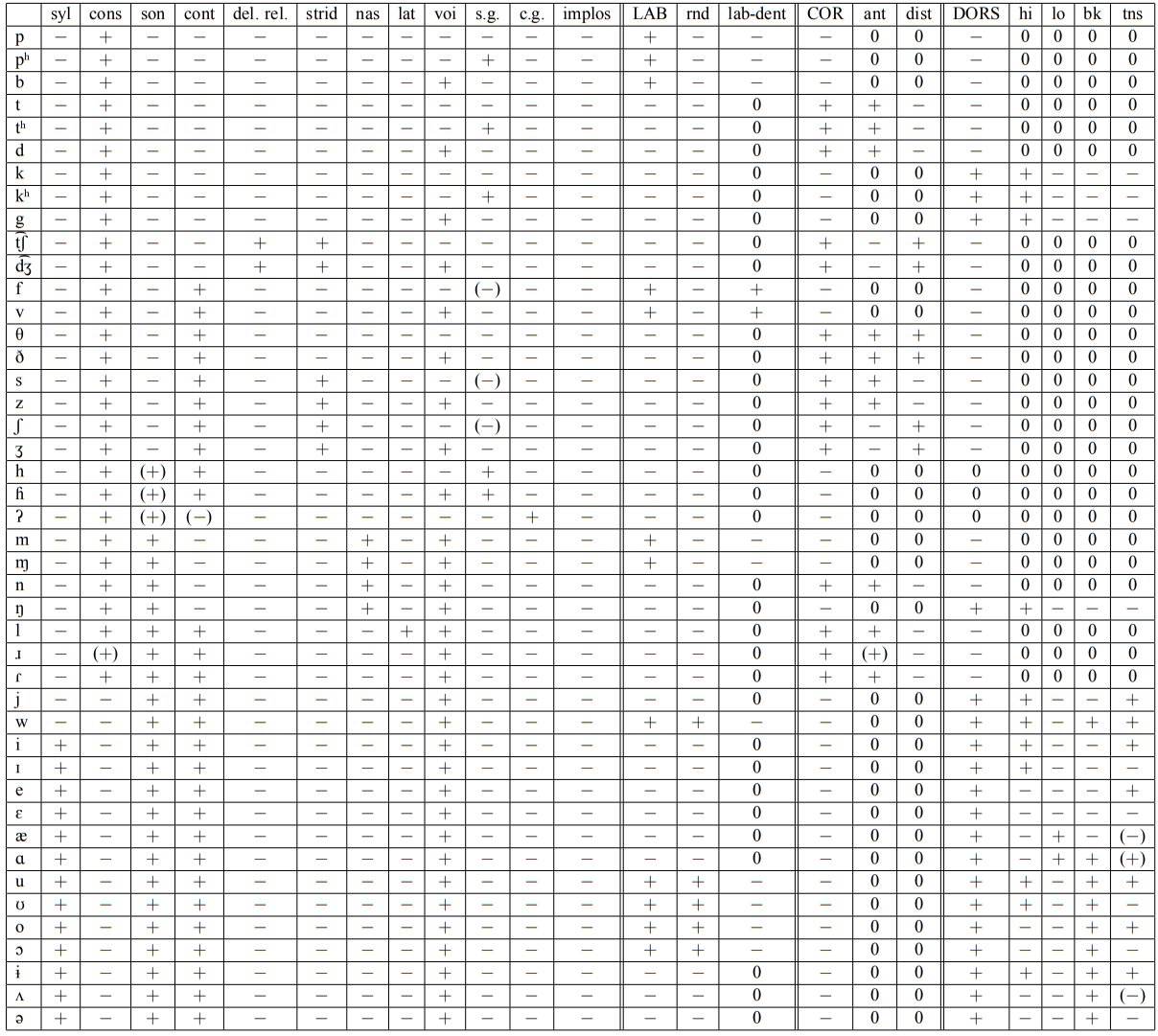
Each letter represents a location at which a number of contrasts intersect. An alphabetic representation is convenient as a writing system for representing words, but it does not represent the contrasts well. For any language, it is possible to specify the contrasts in terms of presence or absence of a given feature of sound or articulation or in some cases both. There have been numerous attempts to specify a set of features that serves for every possible language. Trubetzkoy in the 1930s, Gunnar Fant in the 1950s-70s, Ladefoged, Matisoff, others. Chomsky’s philosophy has demanded that there must be a ‘universal alphabet of phonological features’. Here’s a recent table espoused by the LSA:
Each segment represented alphabetically is considered a combination of values (in the rows of the table) of the features listed in the column heads of the table. Definitions in terms of sound or articulation or often both are attempted in the linked document. These are not always easy to specify as perceptual variables. The syl (syllabic) feature and its contrast with the cons feature may be a function of relative amplitude, for example, but the picture is not clear cut. Labels are sometimes used beyond their definition, as e.g. pharyngeal and RTR (retracted tongue root), both of which in some languages at least are side effects of projecting the epiglottis into the air stream above the larynx. The epiglottis is an active articulatory organ in some languages around the world, one of a number of facts that are inconvenient for such schemes of proposed language universals.
Researchers at Haskins describe phonological contrasts in terms of actions or gestures specified in terms of perceptible intended targets (culminations of gestures) which are not always fully attained. They do not construe these as open-loop ‘emitted behaviors’ or the like, and a straightforward restatement in PCT terminology as controlled perceptions is transparently evident. They’ve done some nice modeling.
Contextual inputs to word recognition are many and diverse, as discussed here, in CSGnet posts, in B:CP, and elsewhere.
You’re not responding to the claim that we control articulatory perceptions in imagination, you’re just ignoring it. I have cited evidence above for this claim.
Segmental phonemes represented by letters are probably a descriptive convenience of linguistics (and of anybody else who wants an alphabetic writing system). They are not the only way that linguists represent the phonemic contrasts between words. The controlled perceptions by which we make the flip-flop flip to this word or flop to that word are probably both articulatory and acoustic, exploiting the way that these modalities are physically coupled in the environment, but only the articulation is directly controllable for whole syllables or words unless you s l o o w w w t h h e e e m m m w a a a a y y d o u w w n. These perceptions occur concurrently, but their durations do not neatly align with the boundaries asserted by an alphabetic representation and the control of each can be and often is a disturbance to concurrent, next, or prior ‘phonetic’ perceptions, which is just fine so long as the flip-flops pick the right winner.
The flip-flop mechanism, by the way, accounts for the old ‘pandemonium’ idea.
Rounding this back up to the topic, the substitution tests of linguistics are a way of identifying controlled variables. They are an application of the Test for Controlled Variables to the data of language. In the last few posts we’ve drilled down into the identification of syllables and words and the control processes for keeping them distinct from one another in socially institutionalized ways so that recipient can reliably perceive the words that the speaker intends them to perceive. The same methodology of substitution tests applies to other controlled variables that constitute language, as sketched in earlier posts in this topic, and elsewhere.
Thanks for this Bruce. I’ll reply to it when I have a few free days;-) In the meantime, could you give me the time in this video where you start discussing how the auditory and articulatory models of recognition are complimentary:
I think you, like most people, have a habit of assuming you know what people are doing (controlling for) just by looking at what they are doing (the overt behavior). I think it’s called Theory of Mind.
I’m not going to try to convince you that what you say about the complementarity of auditory and articulatory models of recognition is important to me; we’ll just get in a conflict over what my motives really were. So don’t worry about it; there is enough in your post about this complementarity that gives me a good idea of what that’s about.
I should make that more explicit. The pronoun “it” refers to a proposed interaction which comprises your perceptions on one side and my perceptions on the other. If “it” (viewing the video and deciding what you think is relevant) is not that important to you then “it” (singling out some part of it that I imagine you might consider ‘relevant’ and thereby seeming to say that most of it is irrelevant fluff that you don’t need to look at) is not that important to me. The Fast Forward button works for anyone and I can’t make your judgements of relevance for you.
The point of my writing the above post is not to convince you but to get into the long-term record some of my views about the nature of language, the foundations of a PCT science of language, and what that can tell us about modeling control of perceptions at higher levels of the hierarchy.
I haven’t mentioned in this topic that above the level of phonetics these are collectively controlled variables. The extant alternative to the study of collective control is the ‘language universals’ view. In phonetics and phonology this is essentially a claim that the phonetic perceptions and the phonological features (variables which in PCT terms must be controlled as means of controlling the contrasts between words) are constrained as ‘natural kinds’, and now and then some linguist or psycholinguist attempts a specification of some physical or cognitive constraints that are supposed to make them universal across all possible human languages. Above the level of word contrast, language universals are supposed to be due to a genetically innate ‘language organ’ that is unique to humans.
Fowler and Turvey published a chapter in an edited volume titled Information processing in motor control and learning (G. Stelmach (Ed.), New York: Academic Press, 1978) presenting what they claimed was evidence that PCT (at that time just called Powers’ control theory model) was all wrong. Bill wrote an unpublished reply and I published a reply in my “Nature of Behavior” paper (starting on p 201, so you don’t have to read the whole paper;-). So pardon me if I don’t believe that they are the best source of evidence for the motor theory of speech recognition.
I will say that, of those two authors, Fowler is at least possessed of some integrity since she was the decision editor on my “Perceptual Organization of Behavior” paper that she approved for publication in JEP:HPP even though it made an unfriendly reference to the 1978 Fowler/Turvey paper. I’m pretty sure that the rest of the references you sent are on a par with the Fowler/Turvey chapter.
That wider context is acoustical, not articulatory.
Apparently the speech recognition people don’t think so.
So we recognize speech by setting reference signals for articulations that would produce the speech that we can’t recognize? I don’t see how this could work.
It doesn’t work that way; we continuously vary our articulation to produce the continuously varying speech sounds that we intend to produce. The normal loop delay (mainly due to neural transport lag) is very short – probably on the order of 50 msec – and has no effect on the ability to control words as they are being produced. The clearest evidence of this comes from studies of the effect of delayed feedback on speech, which artificially increases loop transport lag by putting a delay in the feedback connection between sound output and input.
This diagram is good but it’s missing a very important little line: the one connecting the articulatory output, A, to the speech input, S. This would make it clear that variations in articulation (A) are the means by which the system controls for producing the desired speech sounds (S).
Actually, except for the absence of the feedback connection from A to S (and a disturbance to A as well; we can talk while eating, for example, even though we shouldn’t;-), this is a reasonable model of how both articulatory and phonetic perceptions could contribute to the perception of speech (at least, when one is speaking. I can’t see how articulation could possibly be involved in speech recognition, however, unless, like Helen Keller, one has learned to recognize facial movements as speech.
Maybe. But I don’t think so.
Of course there different systems involved in producing versus recognizing speech. Speech recognition can’t possibly involve perception of the speaker’s articulations; speech production can (as indicated in your diagram).
I refute it thus: You can only control what you perceive and you can’t perceive what another person is perceiving.
If I ever say these things (and I can’t imagine that I do very often) I do it for rhetorical purposes. I have no idea whether a person actually ever agrees with me or misunderstands me or disagrees with me, for that matter.
To the extent that I do those things, I do them in the hope of getting a person to understand what I’m saying. Hoping is a bit like controlling – very ineffectual controlling – but to the extent that it is control I am certainly not controlling what another person perceives; I am controlling what I perceive in another person’s behavior.
I would have a different perceptual function for every word.
I am just not able to fit this into my understanding of what the test for the controlled variable is about. If the pair test is, indeed, a version of the test for the controlled variable then it must have told us something about the variables people control. Maybe I could better understand the pair test as a version of the test if you could give me an example of one of the controlled variables discovered using the pair test and how the pair test revealed that it is, indeed, a controlled variable.
Right! Though speech sounds could probably also be measured instrumentally once we have built the equivalent of the human perceptual functions that perceive these sounds. To some extent we can already do this; N. B. the speech recognition system in your phone.
I also hear a contrast between lane and skyrocket and between rain and heavy. Indeed, I hear a contrast between lane and “rain” every other word (except lain and reign). Why not just say that each word sounds different from every other word (except homophones)?
I think the term “contrasts” just reflects a theory (the motor theory of speech recognition) that words are distinguished from each other in terms of articulatory features, each of which has two possible states. So 15 articulatory features (binary contrasts) are sufficient to handle the size of the average speaking vocabulary (~ 30,000 words) and 18 features would be enough to distinguish all the words in the English language (~250,000). The table of articulatory feature that you sent has 23 features (contrasts), some of which are apparently trinary, so that could easily handle a language with over 8 million words.
The only problem with this theory is that people can’t perceive most of these articulatory features (we can see lips and, to some extent, the tongue move; but that’s it).
I didn’t see a “citation” of evidence that we control articulatory perceptions in imagination. Maybe if you have described the evidence rather than just cited it I might have noticed.
Maybe you didn’t understand my question. I was asking how we can know that there are phonemes if we have no perceptual input functions for phonemes. I didn’t see an answer to that in the above passage.
Substitution tests, like all tasks, involve control. But they are not really a test for the variables controlled in speech. They do, however, suggest hypotheses about what variables are being controlled.
And the point of my replies to your posts is not to convince you but to get into the record my views of PCT and how it should relate to a PCT science of language.
The point is that acoustic data at the temporal location of ‘a phoneme’ are insufficient for speech recognition systems reliably to recognize that phoneme. Lacking any analog of articulatory perceptions, these speech recognition systems demonstrate nothing about human recruitment of references for them that are imagined to produce the intended word.
Nobody has claimed that the listener can perceive the speaker’s articulatory perceptions. Language users can and do imagine their own perceptions of words retrieved from memory, articulatory perceptions along with acoustic perceptions. What you are trying to dispute is the role of imagined articulatory perceptions in human speech recognition as well as in human speech production.
Every utterance in normal speaking is more or less ambiguous. Humans rarely notice the great numbers of ambiguities that computers have to sort out; that is, we sort them out before they come to awareness. The acoustic input goes to PIFs for plural words. Higher-level systems attempting to construe the utterance within which the given word is occurring receive inputs from all of those words. From each ‘reading’ of the input which those systems are currently attempting to control are sent reference signals for controlling the sequence of words in that particular construal. The reference signals copied to perceptual input are relatively weak. The combination of the imagined and environmentally input signals is of different strengths for the different ‘candidate’ words. A categorizing function identifies one word and ‘ignores’ the other candidate words. I assume this is done by flip-flop cross-connections, but if you have some other mechanism for modeling categorizing it will accomplish the same thing.
So would I. Then what? Plural PIFs for words receive the same perceptual input. In a ‘pandaemonium’ process, one word is selected. Somewhat like a Necker cube or the hag/maiden illustration, this selection can suddenly switch to a different word as context continues to unfold.
The horse raced past the barn fell down.
Because he always jogs a mile seems a short distance to him.
Articulatory changes are subject to laws of physics and facts of physiology. Retrieving the tongue from its articulation of t and moving the lips to articulate p or even moving the tongue to articulate k takes far longer. There are other reasons as well, due to the time it takes to ‘notice’ the mispronunciation at a higher level which controls the correction, and because categorial perception is discontinuous.
Remember the experiment in which headphone noise masks acoustic feedback to the speaker? You’re not as certain you’re pronouncing words correctly, but you’re able to continue speaking unimpaired. Observationally, the speaker tends to articulate more carefully.
You perceive many things which are not directly accessible to your perceptual organs. They are nonetheless your perceptions.
Your perceptions of what other people are perceiving are indispensible to social life. They may be completely off base, and you may try to verify them, or you may simply assume that e.g. the person standing on the curb wants to cross the street. In particular, the experimenter’s perception of what the subject is perceiving from their point of view is indispensible for the experimentally constrained social interaction that we call the Test for Controlled Variables.
The pair test identifies controlled perceptual variables like the phonological features that appear as labels of the columns of the matrix that I posted, and it identifies that they co-occur more or less at or near the locations indicated by the alphabetic symbols for ‘phonemes’ such as those that appear as labels of the rows in that matrix. In the writer vs. rider case, the phonetic features by which speakers of American English usually contrast t vs. d are not present, and the contrast between the words is controlled by controlling the relative length of the preceding vowel. So the pair test identifies the contrasts between words in the tested language, the locations of the points of contrast relative to one another, and the phonetic means of controlling the contrasts. You may not like it, but that is what the data show.
‘Phonemes’ are represented by alphabetic symbols such as those in the matrix of putatively universal phonological features. The phonemes are a more or less imperfect symbolic representation of the locations of contrast and of the bundles of more or less concurrent phonetic CVs by which the users of the given language control the contrasts between the words of that language. Alphabetic writing is human artifact like taxes, jigsaw puzzles, and crosswalks, a complex collectively controlled perception that we use to control perceptions in addition those that we control by speaking and hearing.
Civil orthographies have come into being in historically contingent ways. In general, they are not ‘the phonemes’ of the language, but they are adequate for a well-trained reader, viz. English spelling conventions (‘phonics’) combined with memory of word and syllable shapes. We ‘know’ that there are phonemes in linguistics to the extent that the linguist is able to devise a system of symbolic representation from which a reader can produce a repetition of what the writer intended to be spoken. That repetition can be phonetically rather different or even quite different from a repetition that the writer would produce, or that another reader would produce, but the contrasts within the system of contrasts controlled by any one reader are congruent with the contrasts within the system of contrasts controlled by another reader of the same language.
You hear many contrasts between those words, not just one.
Here you are articulating a perception that combines your perception of what I have said with your perception of what the motor theory of speech perception says. All three perceptions are incorrect.
Those lexemes don’t come out of nowhere; they have to be perceived in the acoustics.
No, I am disputing the idea that articulatory perceptions, real or imagined, have anything to do with speech recognition.
This doesn’t answer my question. Let me try again: How could setting reference signals for articulations that would produce speech that we can’t recognize improve our ability to recognize that speech? It’s the italicized portion of this question that makes the idea particularly questionable.
You perceive many things which are not directly accessible to your perceptual organs. They are nonetheless your perceptions.
[/quote]
I would love to see a demonstration of control of a perception that is not directly accessible to the controller’s perceptual organs.
Yes, it is a good source of hypotheses about the articulatory variables that might be controlled when speaking; but it doesn’t show that these variables actually are controlled.
Actually, all I hear is that they are different when they are said one after the other.
By the way, I am participating in this debate only to try to show you how PCT can inform linguistics rather than vice versa. I’ll eventually try to explain what I see as the difference between these approaches to PCT in a separate thread.
PCT is a theory, black letters on white pages, can’t do anything, certainly not inform. What you are saying is that you, Rick Marken, can, or should, inform linguists like Bruce Nevin; not linguistics, because, again, that is just a bunch of theories.
What a rude comment. Why would you not be informed by Bruce. Certainly a scientist with interest in both linguistics and control theory could use both fields of knowledge.
I can see how you would think that. I certainly didn’t intend to be rude. I should have explained what I meant by that comment.
As I said in the discussion with Bruce, I think linguists have made some brilliant observations. One of those is that phonemes can be distinguished from each other better in terms of articulatory than acoustical features. Unfortunately, this has led linguists to believe that recognizing speech involves recognizing both the speech sounds themselves as well as the articulatory means used to produce those sounds. This idea from linguistics has been used to inform Bruce’s PCT model of speech (at least as verbally articulated), which involves parallel control of speech sounds and the articulatory means used to produce them.
PCT suggests that this model couldn’t be right. Control of speech sounds requires that it be possible to vary the means (articulation) used to produce those sounds in order to compensate for disturbances that would otherwise prevent them from being produced as desired. Disturbances are things like chewing food while talking or variations in ambient background sound.
The articulatory features discovered by linguists are most likely the states of the articulators that produce the different phonemes when disturbances are not present. A PCT based understanding of speech production would be aimed at (among other things) finding the aspects of the acoustical speech signal that are being controlled and showing how they are controlled by variations in articulation.
I can give an unusual but hopefully useful example of language perception. English is a foreign language for me and I master is very much worse than my mother language, even though I have used it quite much. Using English is very much slower and more unsecure than using Finnish and I believe it is partly because my control structures for it are less routinized and I must work more with my consciousness. For example when I read or write in English I must at the same time speak silently all the words. Still bigger problem this is with listening English. I can follow only if the speaker speaks so slowly and with so long pauses that I have time to echo all the central words in my silent speech. The more the word is unfamiliar the more I have to use my speech organs mouth and tongue to repeat it. The more familiar words are repeated more clearly just in imagination.
I must admit that even though that above is based on my personal experience, it is also in line with my theoretical idea, that thinking, especially conscious conceptual thinking, is speaking in imagination. So before I can detect and understand a word or sentence I hear, I must think it which means I must speak it silently, imagine my speaking it.
Bruce or others, do you know any research about that hypothesis? For example, do listeners speech producing neurons activate when they listen?
Sorry I forgot to say that because of my experience it seems to me that, against what Rick says, we often and perhaps always somehow use our articulatory machinery when perceiving linguistic messages even though we are seldom conscious about it.
This goes back to message 24 in this thread. I have a simple question for both Bruce and Rick: "Assuming an appropriate situational context, are these two acoustically unrelated statements the same or different: (1) “I’m going upstairs”, (2) “If you want me, give me a shout.”?
I’d give your answer a C or C-. As a minimalist exercise you are technically correct, so it’s not an F, but you are asserting that two things can be both the same and different without explaining how this can be true. You would have got a better grade if you had said in which way they were the same and in which way they were different.